Python 데이터 수집 및 가공(5)
데이터 프레임(ch4)
데이터 프레임 만들기
데이터 프레임은 표라고 생각하면 됨
- 열=속성=변수(칼럼)
- 행=로row=케이스
판다의 pd.DataFrame을 이용해 데이터 프레임 만들기
df = pd.DataFrame({'변수명':[’속성’, ‘속성’] ‘변수명2’:[’속성’, ‘속성’]})
값을 불러오기 위해서는 df명을 한 번 더 써줘야 함
df_fr = pd.DataFrame({'제품':['사과', '딸기', '수박'],'가격':[1800, 1500, 3000],'판매량':[24,38,13]})
df_fr
특정 변수의 값 추출, 합계, 평균
#데이터프레임 만들기
df_fr = pd.DataFrame({'제품':['사과', '딸기', '수박'],
'가격':[1800, 1500, 3000],
'판매량':[24,38,13]})
# 콤마 뒤에서 줄바꾸기 해도 됨
df_fr
#추출하기
df['제품']
#합계
sum(df_fr['가격'])
#평균
sum(df_fr['가격'])/df_fr.shape[0]
sum(df_fr['가격'])/len(df_fr['가격'])
#변수의 개수 - len을 이용해 평균을 구할 수 있
len(df_fr['가격'])
#len(df_fr)도 가능함, 결측치를 포함해서 데이터 프레임의 길이를 반환만든 데이터 프레임 csv파일로 저장
to_csv()
df_fr.to_csv('파일명.csv')
#인덱스 제외 저장
df_fr.to_csv('파일명.csv', index = False)외부데이터 이용하기
excel
- 워킹 디렉터리 (주피터 랩 목록)에 사용할 파일 (csv, excel 등) 삽입
- pandas의 read_excel()을 이용해 파일 불러오기
df_exam = pd.read_excel('excel_exam.xlsx')
*df_exam =데이터 프레임 명
pd.read_excel(’파일명.확장자’): 판다스의 기능 불러오기
csv
csv: comma-separated values: 파일의 값이 쉼표로 구분된 형태
- 워킹 디렉터리에 csv파일 삽입
- pandas의 read_csv()이용하기
데이터 분석 기초
명령어
데이터프레임.명령어()

exam.head() # 앞에서부터 5행까지 출력
exam.head(10) #앞에서부터 10행까지 출력
exam.tail() #뒤에서부터 5행까지 출력
exam.tail(10) #뒤에서부터 10행까지 출력
exam.describe()을 할 경우 숫자로 된 변수 요약 통계량만 출력이 됨.
exam.describe(include = 'all')을 입력할 경우 문자로 된 변수 요약 통계량도 볼 수 있
exam.std()도 가능함

mgp.describe(include='all')
을 통해서 나타낸 요약 통계량 → 문자로 된 변수에 한 해 count(값의 개수)/unique(중복 제거 범주 개수)/top (최빈값)/freq(최빈값 빈도- 가장 많은 값의 개수)를 알 수 있으면 숫자로 된 변수는 NaN으로 나타남
df.shape ( 행, 열 수 구하기)
df.shape #행, 열 출력을 통해 데이터가 몇 행, 몇 열로 구성되는지 알 수 있음
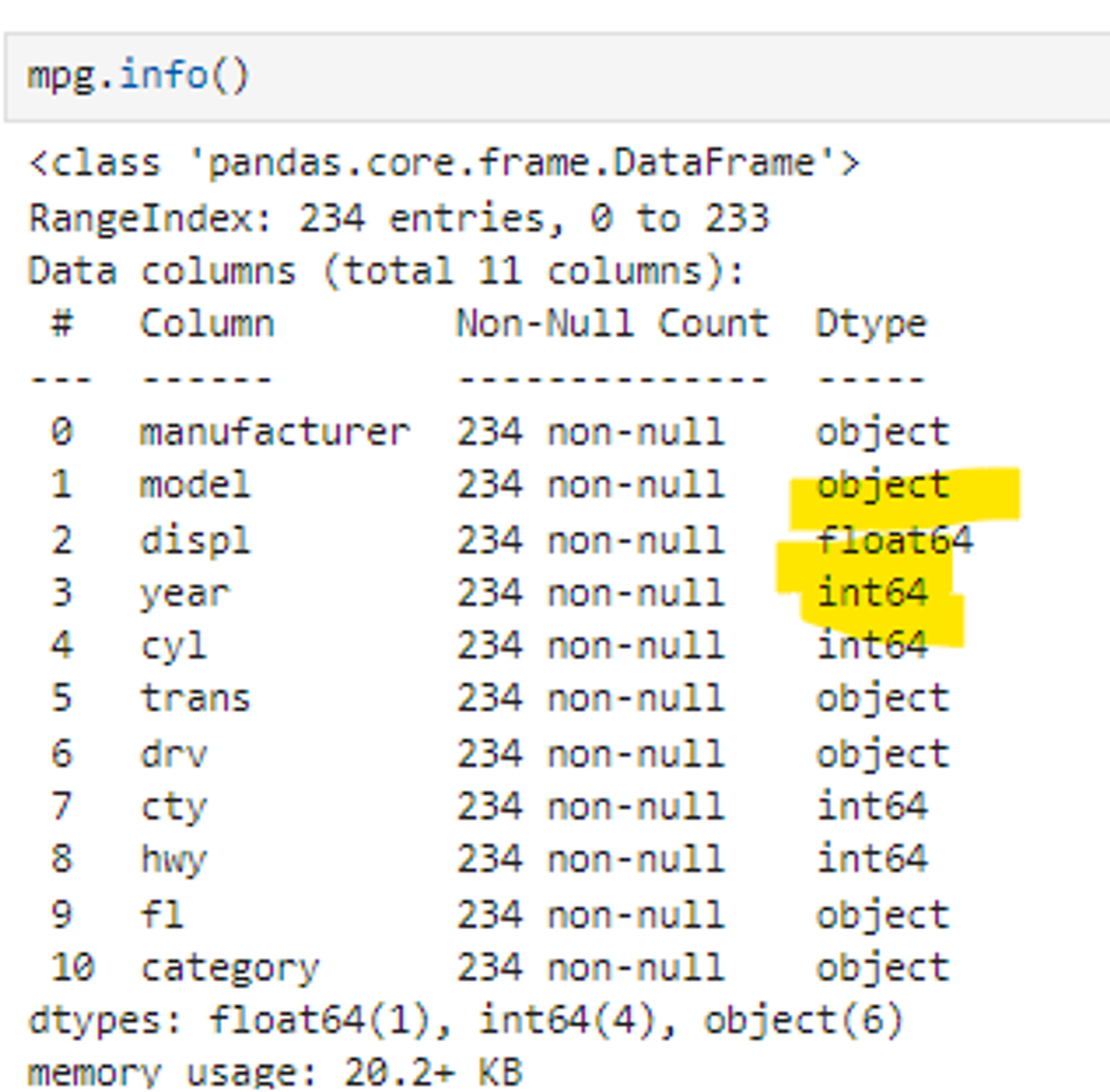
df.info()
- Dtype에서 ‘object’는 문자로 된 변수, ‘float64’는 소수점이 있는 실수, ‘int64’는 소수점이 없는 정수를 의미
함수와 메서드의 차이
내장함수
- 가장 기본적인 함수형태, 함수 이름과 괄호로 사용함.
- 파이썬에 내장되어 있어서 별도로 패키지를 설치하지 않아도 됨
sum(var)
max(var)
패키지함수
- 패키지 이름을 먼저 입력한 다음 점을 찍고 함수 이름과 괄호 입력
- 패키지 로드 후 사용 가능
import pandas as pd
pd.read_csv('exam.csv')
pd.DataFrame({'x':[1,2,3]})메서드 함수
- 변수가 지니고 있는 함수
- 변수명을 입력한 후 (.)을 찍고 메서드 이름과 함께 사용
df.head()
df.info()메서드는 모든 변수에 사용할 수 있는 것 x, 변수의 자료 구조에 따라 사용할 수 있는 메서드가 다름 ex. head() 는 데이터 프레임에 들어 있는 메서드라서 데이터 프레임에는 사용할 수 있지만 리스트에서는 사용할 수 없음
type() 함수를 통해 변수의 자료를 알 수 있음
ex. type(df) → pandas.core.frame.DataFrame →df라는 뜻
변수명 바꾸기
데이터 분석을 하기 전에 변수명 수정을 통해 원활한 이해를 돕는 과정
1.데이터 프레임 만들기
df_raw = pd.DataFrame({'var1':[1,2,1],
'var2':[2,3,2]})
df_raw2.복사본 만들기 (원본 보존 목적): df.copy()
df_new = df_raw.copy()
df_new- 변수명 바꾸기 df.rename()
- 두 변수 중 ‘var2’를 ‘v2’로 수정

df_new = df_new.rename(columns = {'var2' : 'v2'}) # var2를 v2로 수정
df_new*df = df.rename(index={0:’first’} 이런 식으로 인덱스도 수정 가능

필요한 변수 추출
변수 추출
데이터[’변수’]
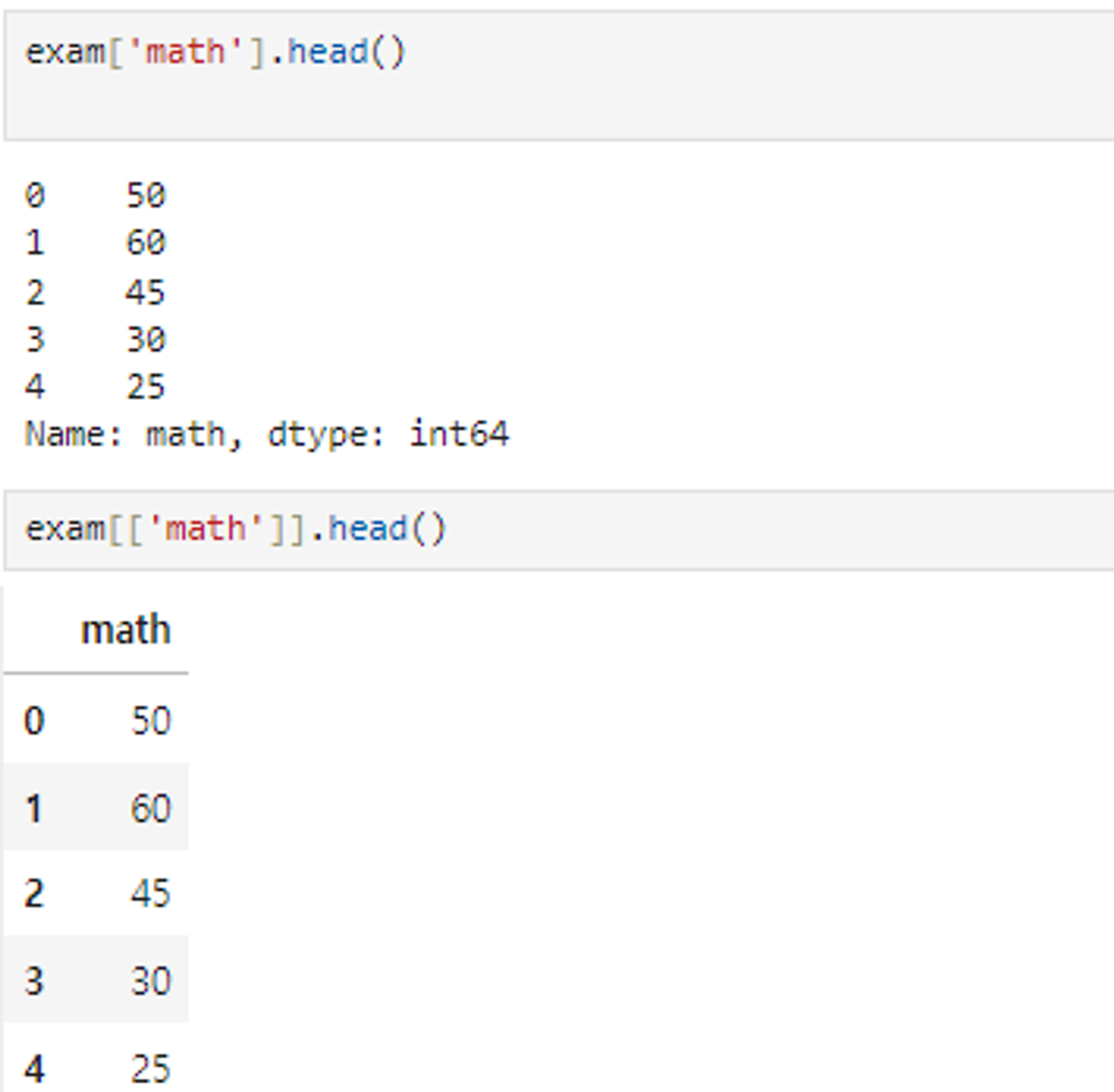
exam['math'] → exam 데이터 프레임에서 <math>변수만 추출하는 기능임 - 시리즈 형태로 추
exam[['math']] 를 할 경우 데이터 프레임 형태로 추출됨
여러 변수 추출하기
‘[]’ 안에 다서 [’]’를 넣어 변수명 나열
exam[['nclass', 'math', 'english']]
#exam['nclass', 'math', 'english'] 이 형태는 안됨 변수 1개만 추출할 때는 [] 하나만 사용 가능
#대신 시리즈로 추출됐음query()와 [ ] 조합하기
pandas의 함수들은 조합해 함께 사용 가능.
- 장점: 코드 길이가 줄어들어 이해 쉬움, 변수 할당 하는 작업 생략 가능
1반 학생의 영어 점수 추출 후 일부만 확인
exam.query('nclass == 1')['english'].head()순서대로 정렬하기
df.sort_values()에 정렬 기준으로 삼을 변수 입력하면 기준대로 정렬 가능
#오름차순
exam.sort_values('math') #math 점수 오름차순 정렬 (낮은사람부터)
#math내림차순
exam.sort_values('math', ascending = False)
#여러 정렬 기준
exam.sort_values(['nclass','math'])
#nclass 오름차순, math 내림차
exam.sort_values(['nclass','math'], ascending = [True, False])groupby() 그룹화
- groupby안에 묶을 필드명은 대괄호로 묶음 ex . 테이블명.groupby([’필드1’, ‘필드2’])
따옴표/쌍따옴표(”.”)
- 의미상 차이가 없음. 일반적인 스트링의 경우 “”
- 문장에 <’>가 들어갈 때 <””>사용, 반대의 경우는 <’>사용
- 리스트 내의 item의 경우 <’> 사용
파생변수 추가하기 df.assign( )
- 변수를 조합하거나 함수를 이용해 새로운 변수를 만들 때 유용함
- exam.assign( )에 새 변수명 = 변수를 만드는 공식을 입력하면 됨
ex. total 변수도 만들고 mean 변수도 만들고 싶을
exam.assign(
total = exam['math'] + exam['english']+exam['science'],
mean = (exam['math'] + exam['english']+exam['science']) / 3)assign 함수 위에서 만든 것을 바로 아래에서 활용하면 오류가 남 (b/c 아직 만들어지지 않음)
새데이터프레임명 = exam.assign~~해줘야됨
df.assign( )에 np.where( ) 적용하기
test 파생변수 생성, 과학 점수 60점 이상이면 pass 미만이면 fall
import numpy as np
exam.assign(test = np.where(exam['science'] >=60, 'pass', 'fall'))lamda (앞에서 만든 변수를 활용해 다시 변수 만들기)
반드시 lambda함수를 이용해 데이터 프레임명을 약어로 입력
데이터프레임 명이 너무 길 때 해당 절에서만 정정해줄 수 있음
long_name.assign(new = lambda x: x['math'] + x['english'] + x['science'])exam.assign(total = exam['math']+exam['english']+exam['science'],
mean = lambda x:x['total']/3)데이터 정제
빠진 데이터, 이상한 데이터 제거하기
결측치
- 누락된 값, 비어있는 값을 정제해줘야 함
- 결측치가 있는 행을 모두 비워버리기도 하는데 그럴 경우 유의미한 값을 지워버리게 될 수도 있기 때문에 주의해야 함
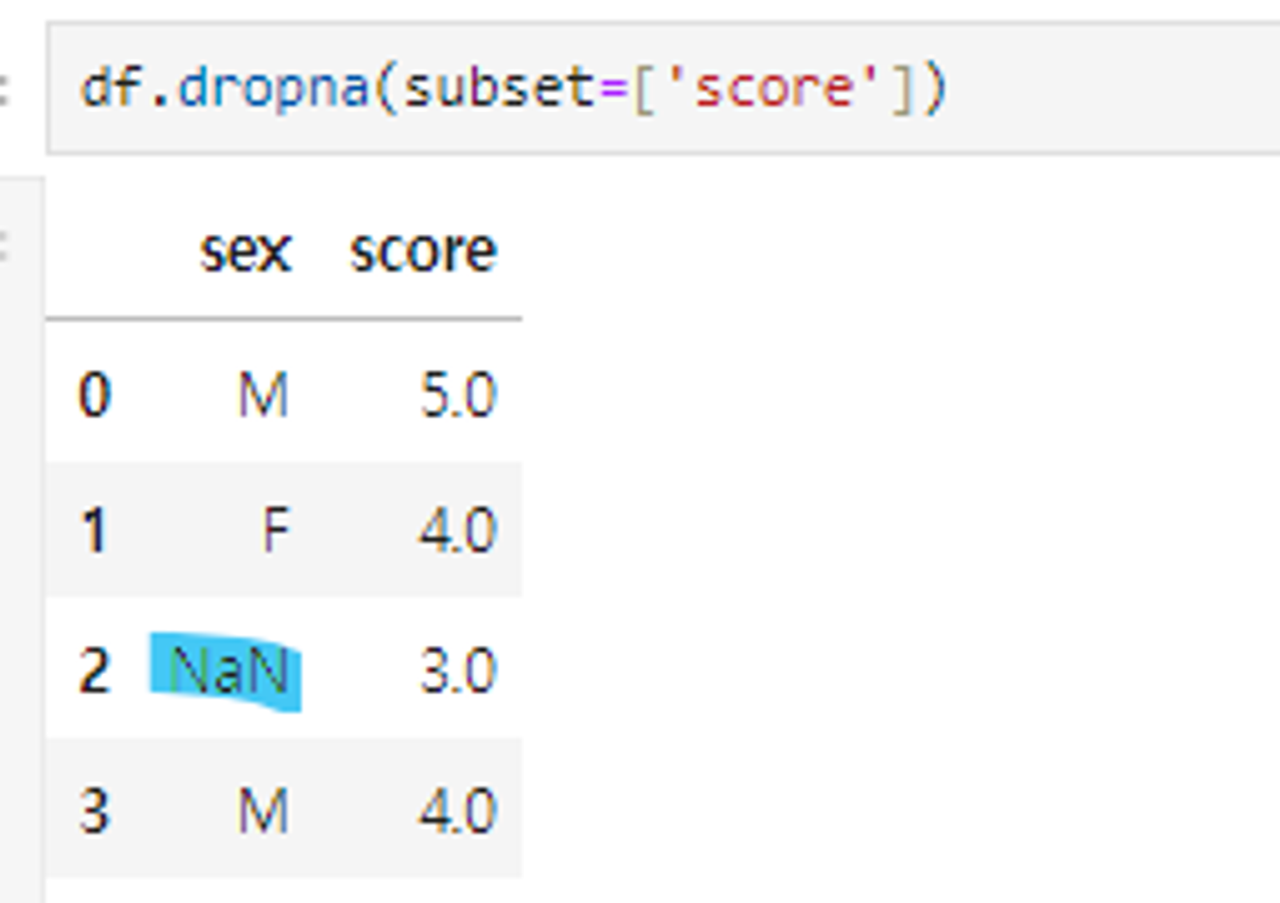
위의 값을 보면 ‘sex’의 3행은 결측치이나 ‘score’의 3.0은 유의미한 데이터로,
3행 전체를 삭제할 경우 데이터 값이 적어짐
이럴 경우 다양한 방식으로 하는데 행을 다 삭제할 수도 있고 최빈값으로 결측치를 대체하는 등 여러 방식을 할 수 있음
loc 함수 (대체함수)
극단치
- 극단치(outlier):논리적으로 존재할 수 있지만 극단적으로 크거나 작은 값
- 극단치가 있으면 분석 결과가 왜곡될 수 있으므로 제거 후 분석
- ex. 20대 후반의 평균 연봉 계산할 경우 제니가 껴있으면 평균이 모집단을 대표하지 못할 수 있음
(상자그림을 통해 극단치를 제거할 수 있음)
seaborn, boxplot
seaborn은 그래프를 그릴 수 있는 라이브러리
boxplot은 상자 수염 그림이라고도 불리며 최댓값과 최솟값을 알 수 있음


iqr(interquartile Range): 제 1사분위수와 제 3사분위 수 사이의 범위를 말함
IQR = Q3-Q1
의미: 데이터의 중간 50% 범위를 나타내며, 데이터 분산 정도와 이상값을 식별하는 데 유용함
*중앙값 : 데이터셋을 오름차순으로 정렬했을 때 중앙에 위치한
IQR 계산법
# 예제 데이터
data = [10, 12, 14, 15, 18, 21, 22, 23, 24, 30]
df = pd.DataFrame(data, columns=['values'])
#IQR 계
Q1 = df['values'].quantile(0.25)
Q3 = df['values'].quantile(0.75)
IQR = Q3 - Q1
#중앙값계산
median = df['values'].median()
'sesac' 카테고리의 다른 글
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | 엑셀 교육(1)_엑셀과 가설검정 (0) | 2024.06.24 |
|---|---|
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 #21 | 파이썬 교육(4)_데이터 분석 및 시각화 (0) | 2024.06.24 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 #17 | 파이썬 교육(3)_반복문 for, while (0) | 2024.06.05 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 #16 | 파이썬 교육(2)_스트링 및 리스트, 마크다운 (0) | 2024.06.04 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 #15 | 파이썬 교육(1)_파이썬 기초의 이해 (0) | 2024.06.03 |

