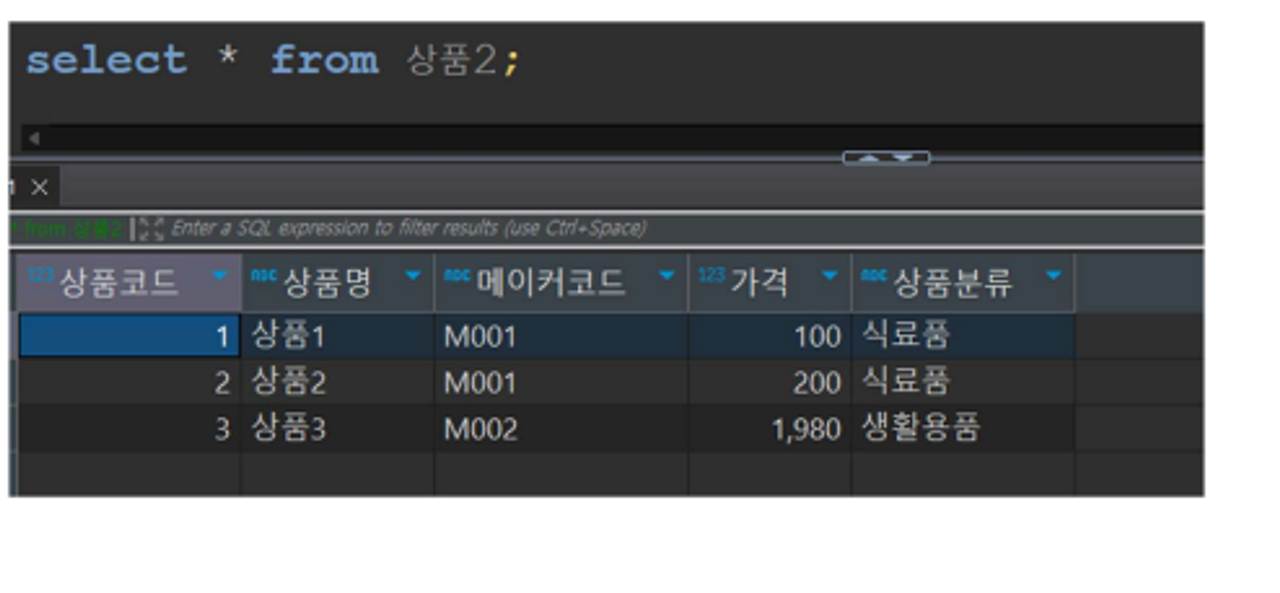
*늘 함수를 사용하기 전에는 SELECT * FROM 테이블을 통해 확인
함수를 통해서 연산하기 - 문자열 연산
ROUND, CONCAT, SUBSTRING, TRIM,
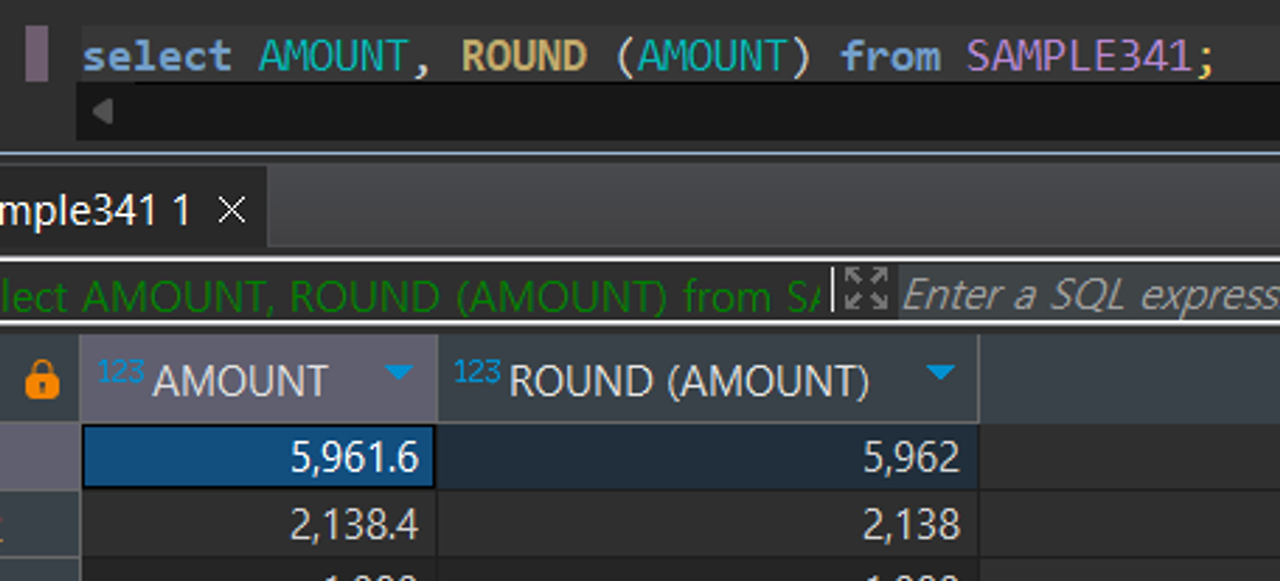
ROUND함수 - 소수점 반올림
추출할 SELECT 뒤에 함수를 입력해주면 됨
ROUND(필드명, N)
기본적으로 소수점 첫째 자리를 기준으로 반올림하지만, (ROUND, N)을 통해 자릿수 지정 가능
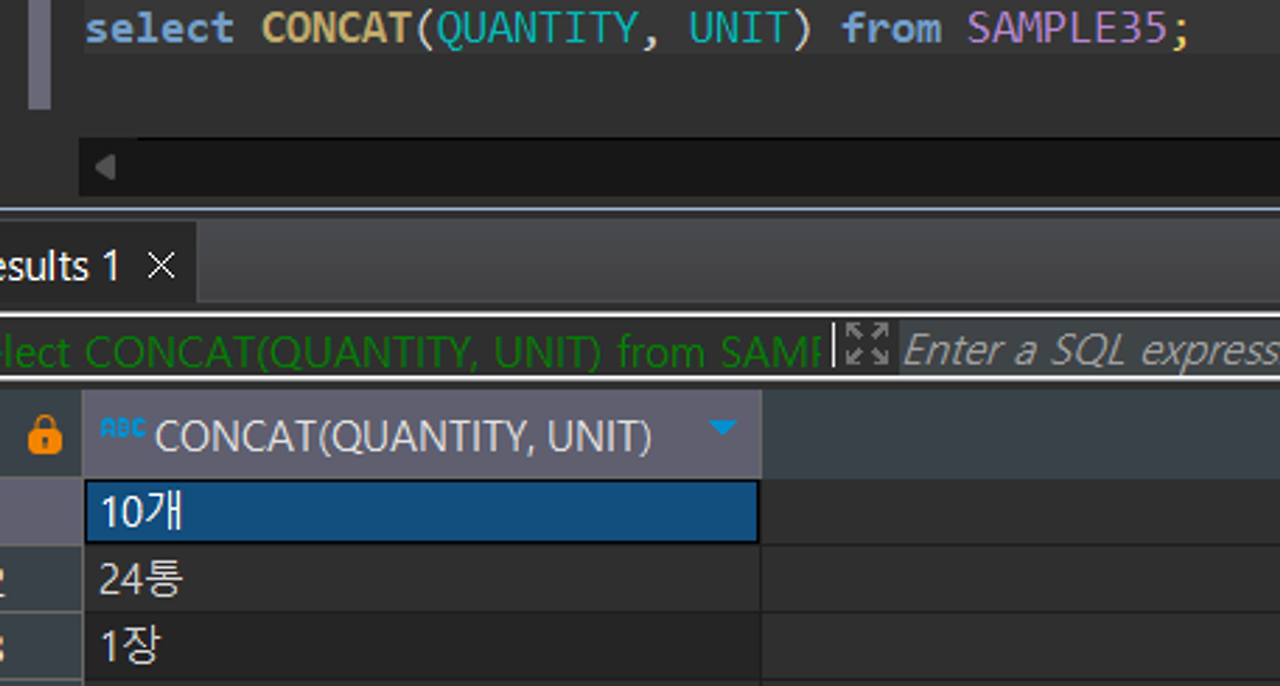
CONCAT - 함수 안에 인수를 넣 문자열 합치기
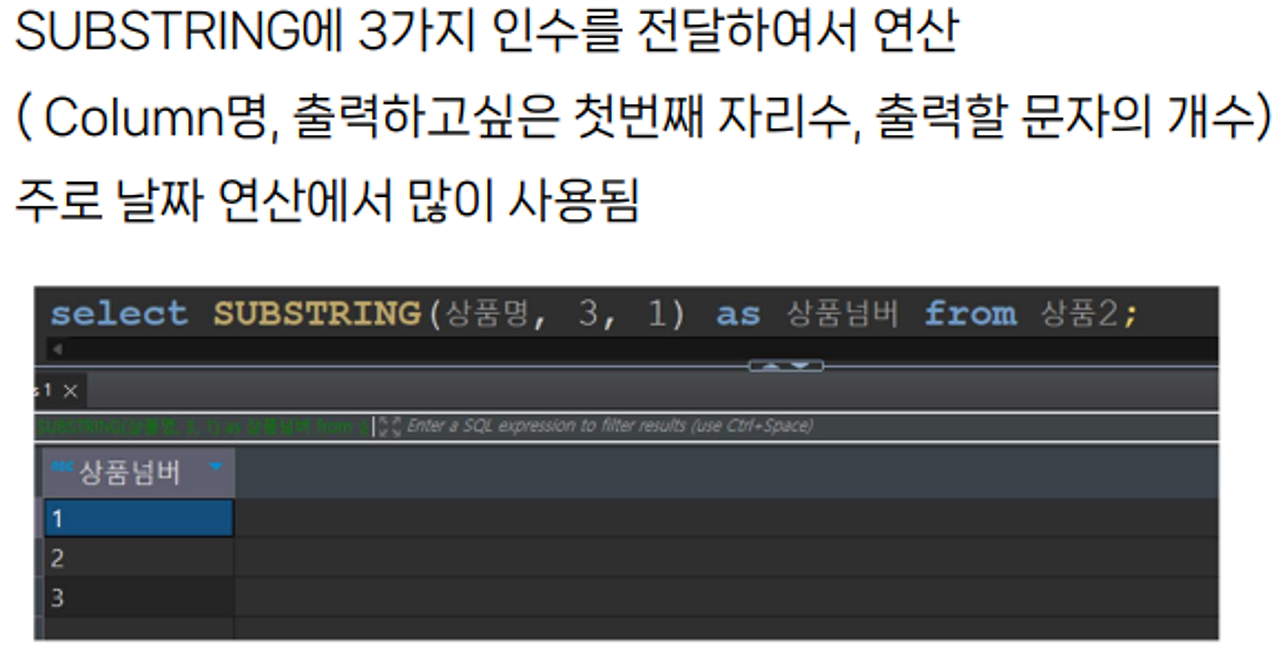
SUBSTRING - 원하는 문자열만 추출
TRIM - 스페이스 또는 문자 제거
TRIM(’ABC ‘) → ABC
Q. track 테이블에서 각 트랙의 이름(Name)과 장르 ID(Genreld)를 결합해 “트랙명 (장르 ID)” 형식으로 출력하세
SELECT concat(name, " (", GenreID, ")") from track;날짜 연산하기
TIME_STAMP 시스템 날짜 출력하기
SELECT CURRENT_TIMESTAMP; / SELECT NOW();
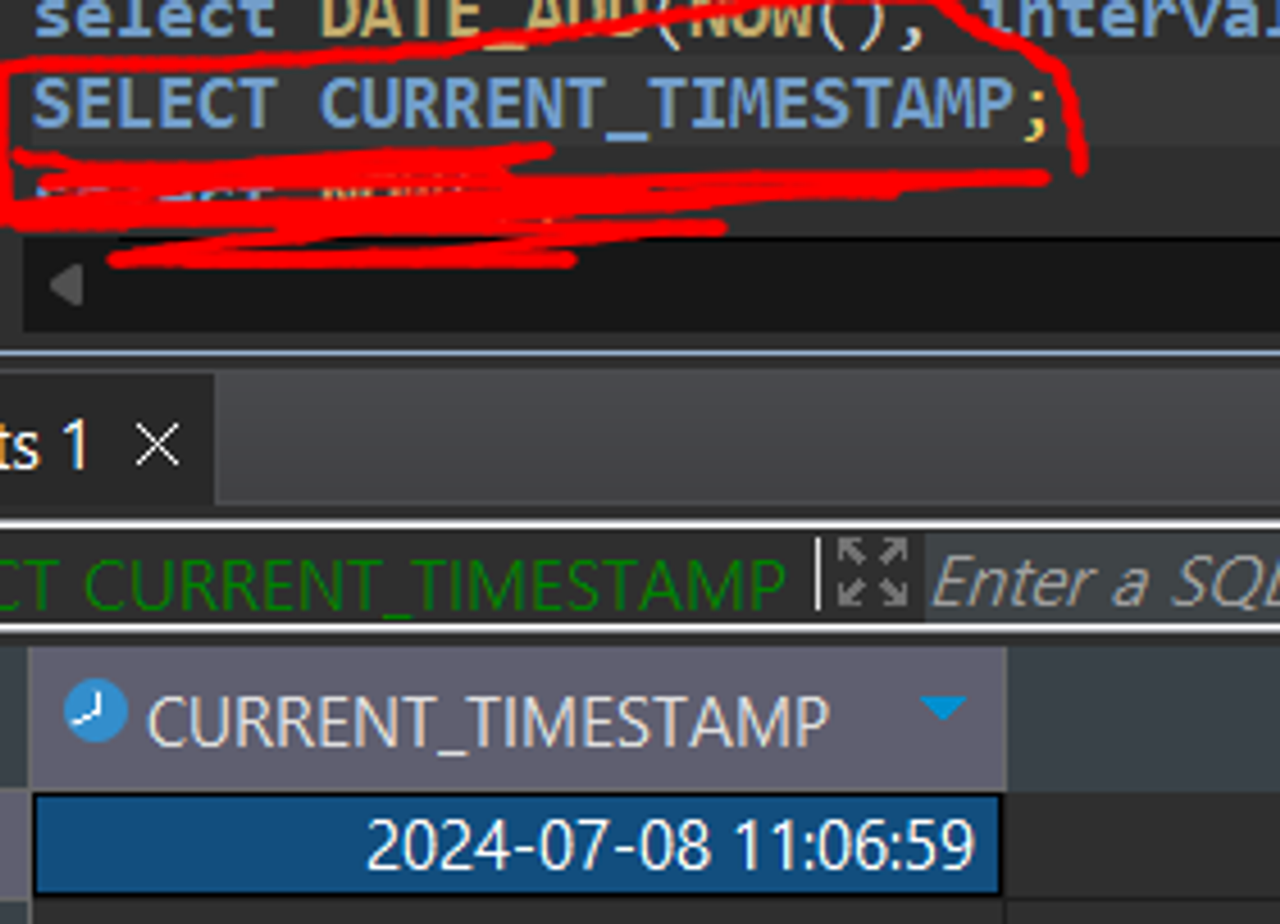
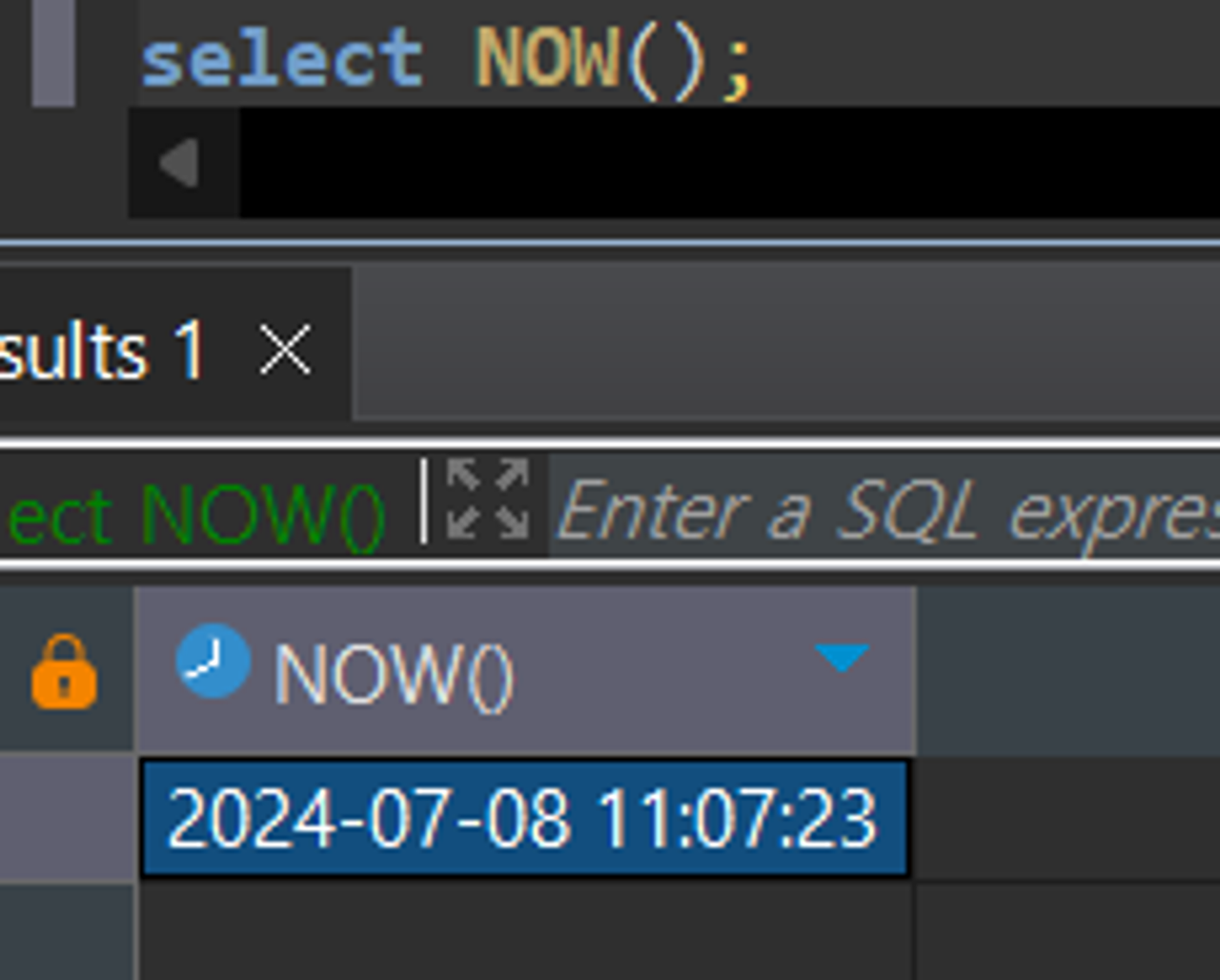
시스템 날짜를 출력하기 때문에 FROM을 생략할 수 있는데 FROM생략 안 할 경우 행 수만큼 날짜값이 나옴
덧셈과 뺄셈 연산
덧셈과 뺄셈
SELECT CURRENT_DATE + INTERVAL 숫자 DAY;
# 내일 연산법 #
SELECT ADD_DATE(NOW(),INTERVAL 1 DAY)다양한 연산 가능
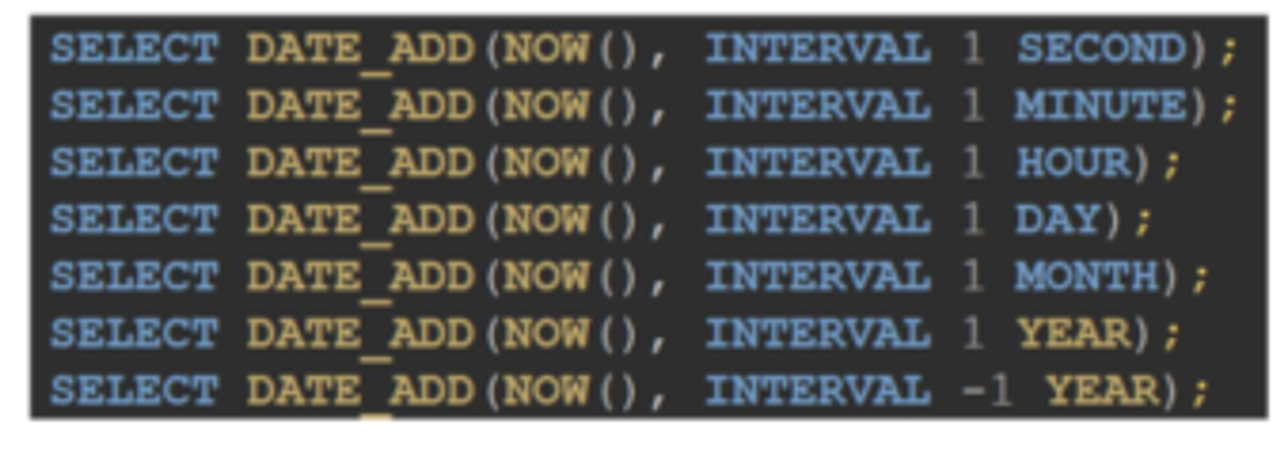
DATEDIFF(’날짜1’, ‘날짜2’)/ TIMEDIFF(’시간1’, ‘시간2’)
SELECT DATEDIFF('2024-07-07', '2024-07-09')
#WHERE문에서 사용할 때#
SELECT * FROM EMPLOYEE WHERE DATEDIFF(HIREDATE, NOW()) >= -8000;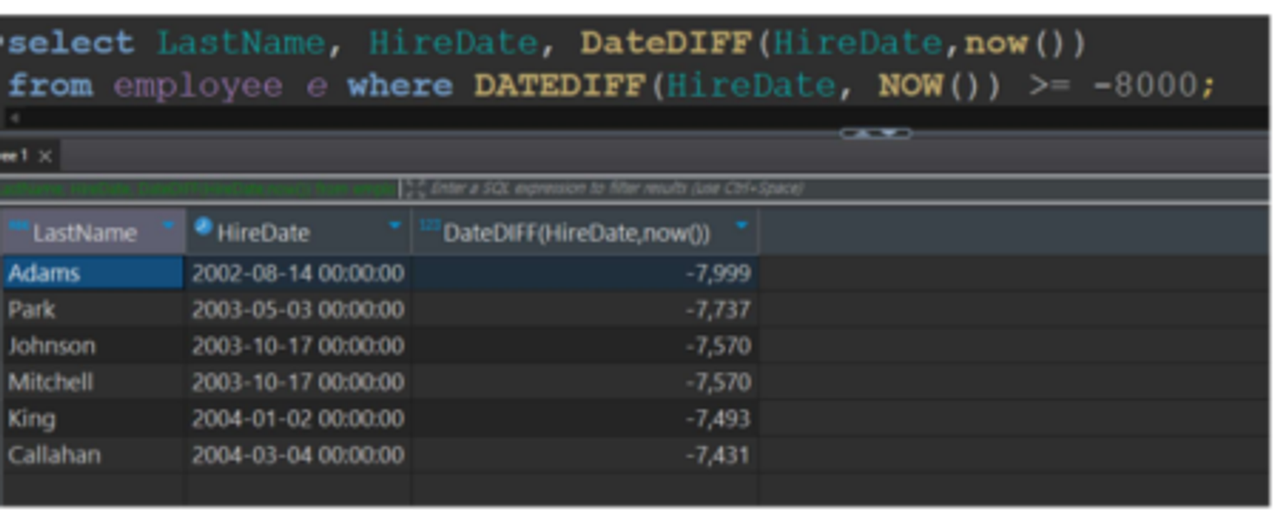
CASE문으로 데이터 변환하기
WHERE 조건문은 파이썬 IF문과 유사함
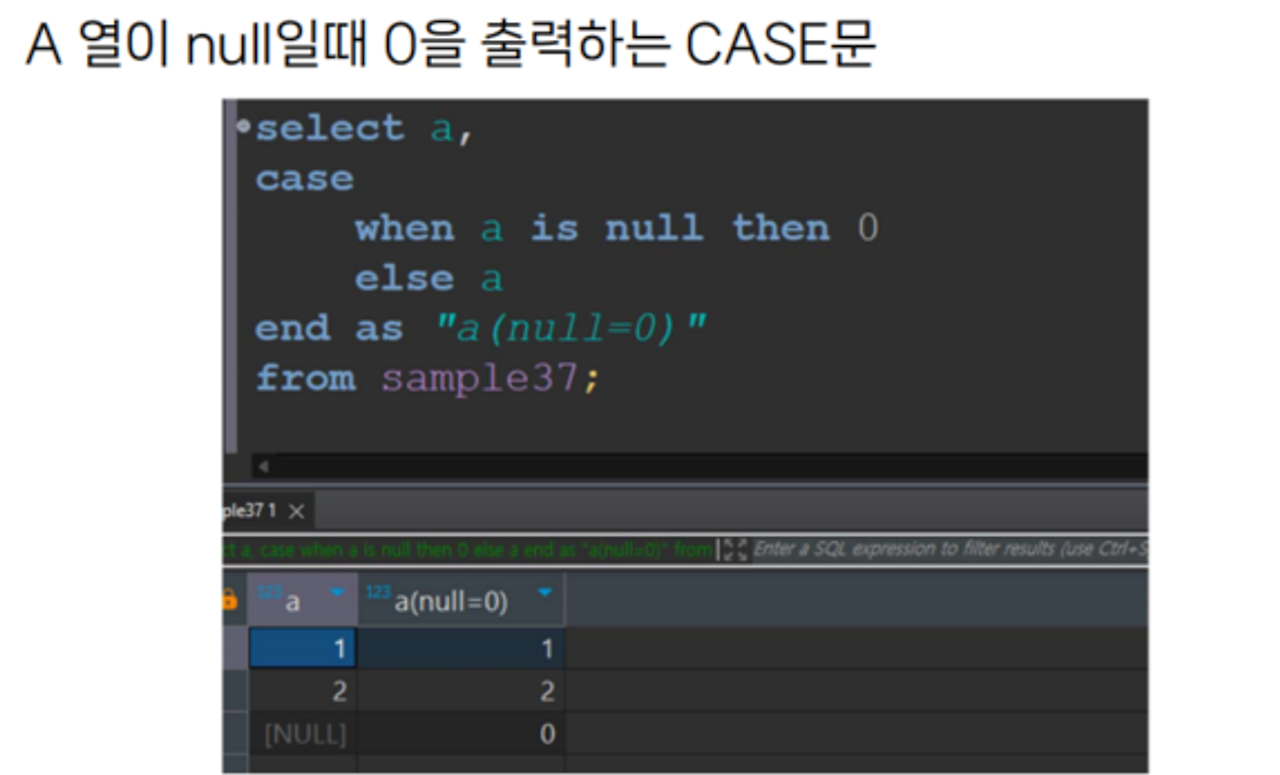
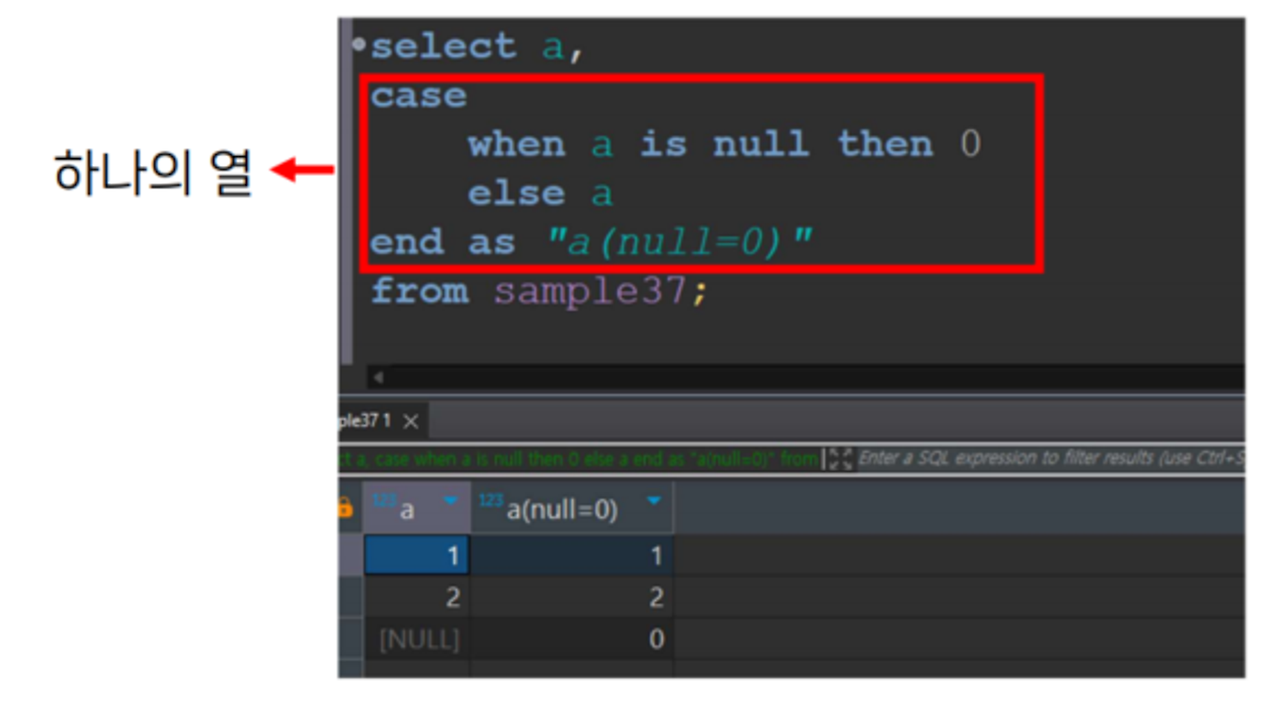
CASE
WHEN 조건식1 THEN 출력1
[WHEN 조건식2 THEN 출력2…]
[ELSE 출력 fin]
END as 필드
CASE문
- WHEN 절에는 참과 거짓을 반환하는 조건식을 기술
- ELSE 생략시, ‘ELSE NULL’로 간주
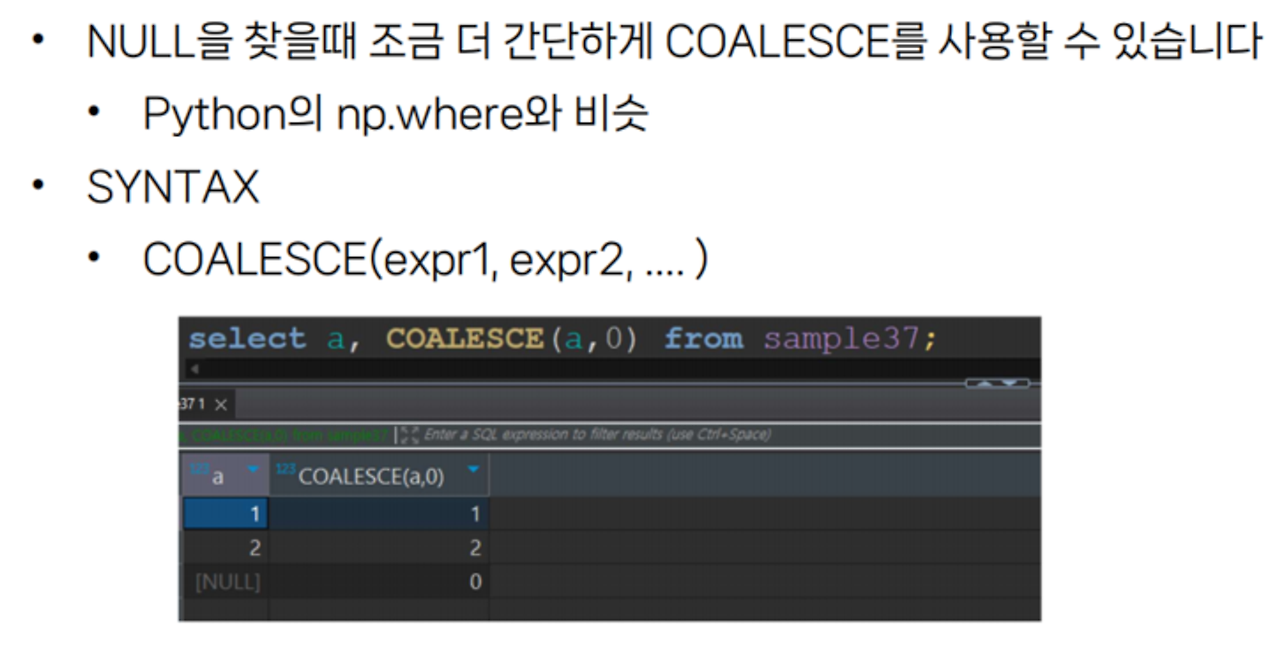
COALESCE(expr1, expr2, …) - NULL값 쉽게 찾기
null 값을 찾고 싶으면 coalesce로 기억하면 됨
Case문은 보통 숫자로 이루어진 코드를 문자열 변환할 때 ( 가독성 목적) 사용
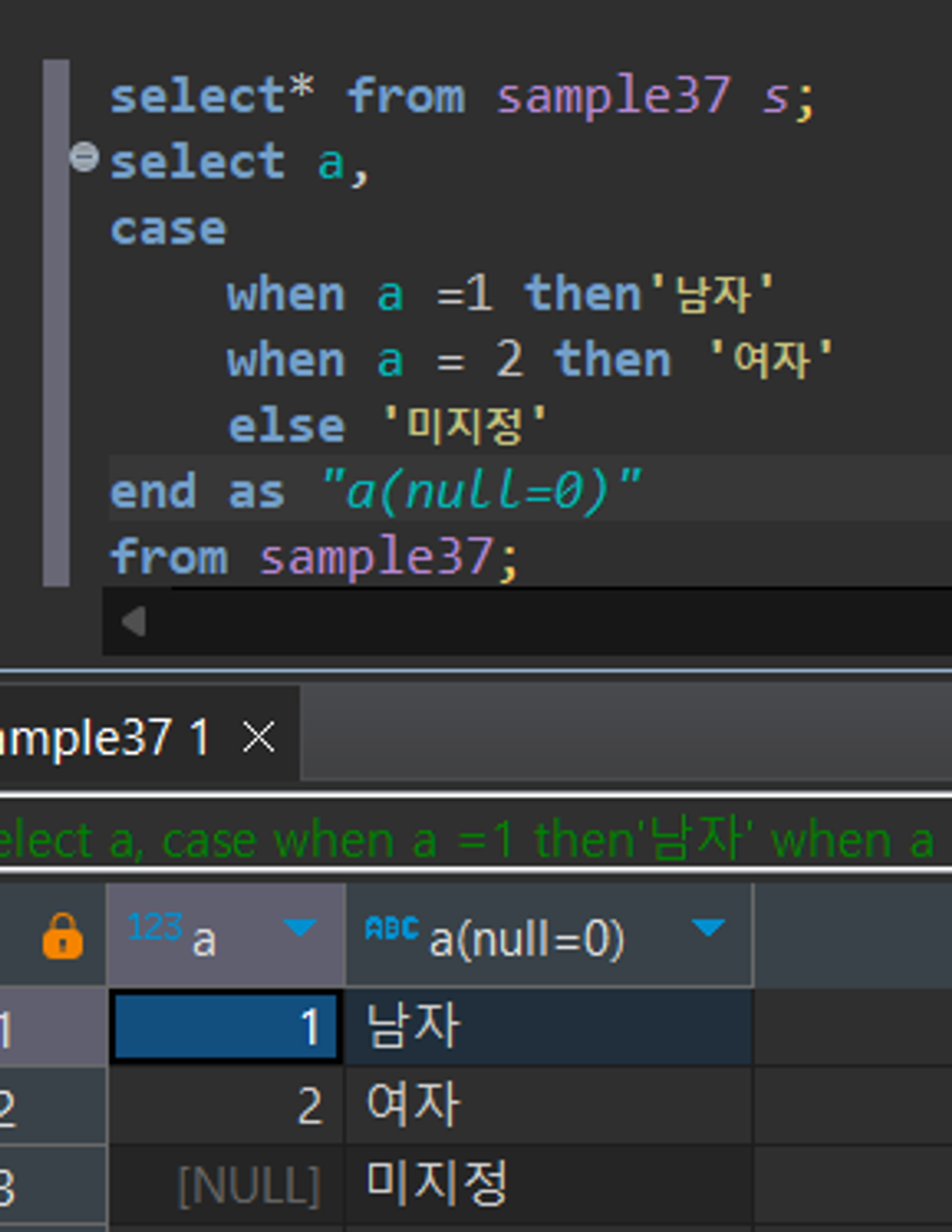
예를 들어 1은 남자, 2는 여자라는 체계가 있다면?
when a =1 then ‘남자’
when a=2 then ‘여자’
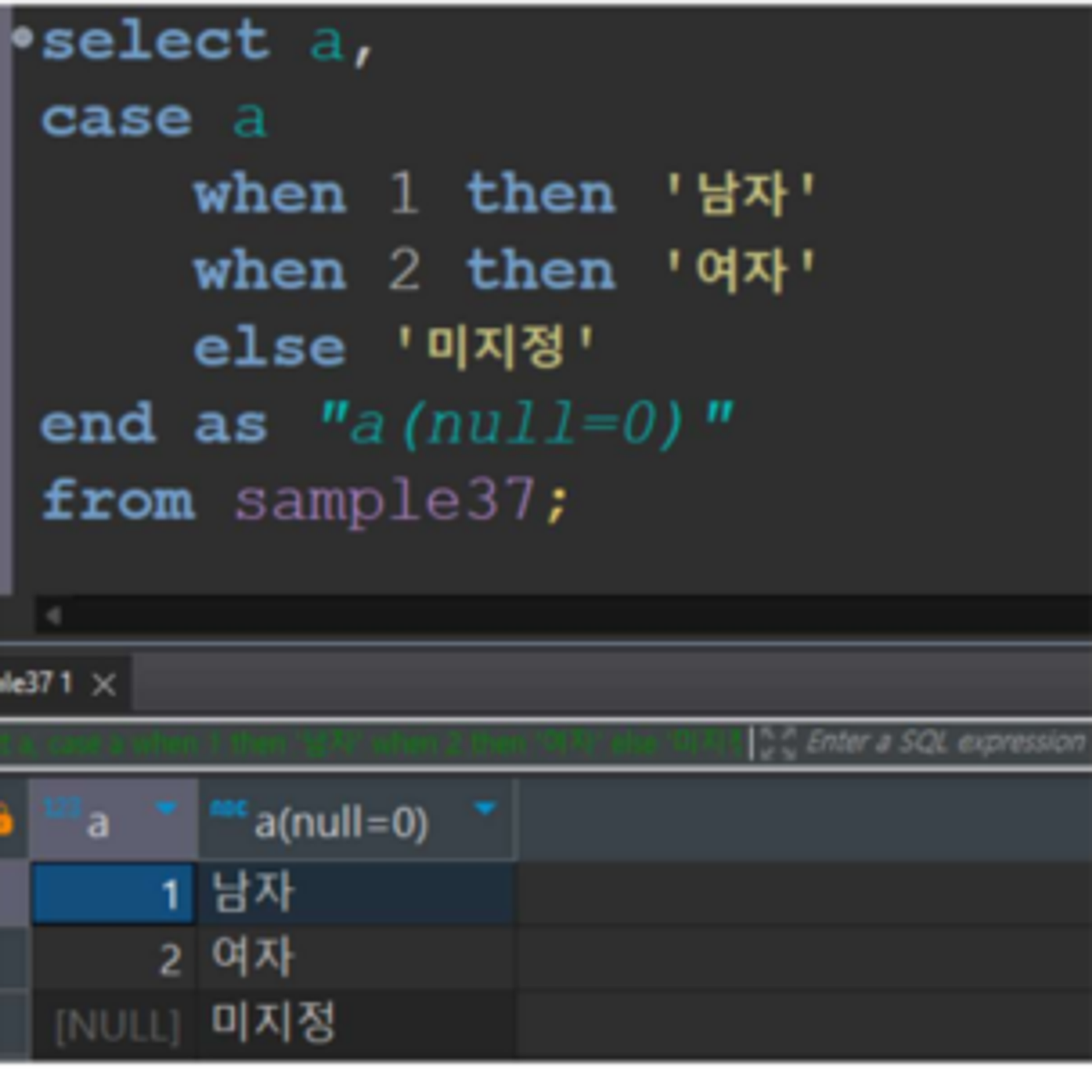
Q. 테이블 A가 1일 때는 남자, A가 2이 때는 여자, NULL일때는 미지정 출력
CASE 쉽게 비교하는 법 - 상수 비교
CASE 문에서 비교할 항목을 지정하고, WHEN에는 1이나 2처럼 비교할 값만 기술하는 것도 가능
주의사항
- CASE문은 WHERE이나 ORDER BY 구에서 사용 가능
- ELSE를 생략시 ELSE NULL이 되는 것 주의 (생략하지 않는 것 추천)
- WHEN에서 NULL을 사용할 경우 ‘IS NULL’사용해야
Q.invoice 테이블을 사용하여 각 주문의 InvoiceDate를 기준으로 분류하여 InvoiceID와 InvoceDate, 주문 년도 를 출력하세요. ( 2007년 데이터, 2009년 데이터, 2009년 이후 데이터 로 분류)
#내가 쓴 식#
select invoiceid, invoicedate, year(invoicedate) as year,
case
when year(invoicedate) = 2007 then '2007'
when year(invoicedate) = 2009 then '2009'
else '> 2009'
end as order_year
from invoice;case문 넣기 전에 (,) 안 해서 오류났음
#멘토님 답
select invoiceid, invoicedate, substring(invoicedate, 1, 4),
case substring(invoicedate, 1, 4)
when '2007' then "2007년 데이터"
when '2008' then "2008년 데이터"
when '2009' then "2009년 데이터"
else "2009년 초과 데이터"
end
from invoice;Q2. Invoice 테이블을 사용하여, 각 주문의 InvoiceDate로부터 2011-12-31까지의 경과일을 계산하고, 경과 기간을 분류하세요 (ex: 1년 이내, 2년 이내, 3년 이내 )
#내 답
select invoiceid, invoicedate,
case
when datediff('2011-12-31', invoicedate) <= 365 then "1년 이내"
when datediff('2011-12-31', invoicedate) <= 365*2 then "2년 이내"
when datediff('2011-12-31', invoicedate) <= 365*3 then "3년 이내"
else "3년 초과"
end
from invoice;데이터 추가 수정 삭제
INSERT 행추가
Insert into 테이블명 values(값, 값, 값, 값…)
- 행을 insert를 통해 추가하려면 열의 값을 지정해야 함
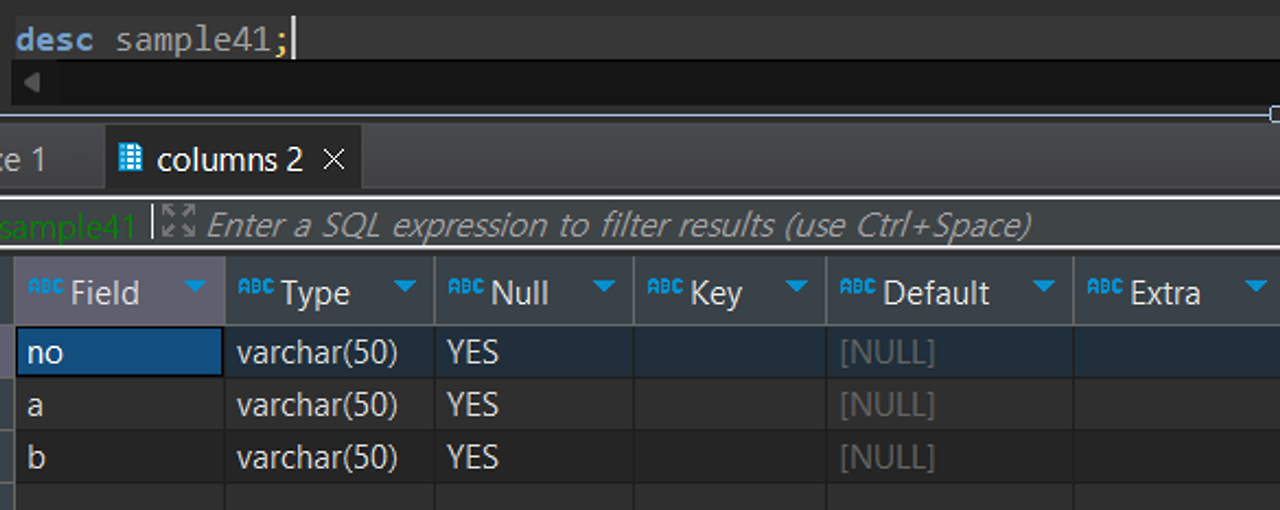
- 그렇다면, 각 열에 어떤 유형의 데이터를 저장할 수 있는지 desc 명령으로 확인해야 함
*예제
sample41 데이터는 모든 열이 varchar type이고, 최대 길이가 50인 문자열을 저장할 수 있음
확인이 끝났으면 insert
insert into sample41
values(1, 'abc', '2024-07-08');- 행에 default 값이 지정되어 있다면 values를 지정하지 않았을 때 자동으로 그 값이 저장될 수 있음
- not null 제약이 걸려있을 경우, null 값 넣을 수 없음.
DELETE 행 삭제
delete from 테이블명 where 조건식
- where문을 통해 조건을 지정하지 않으면 모든 데이터를 삭제
- 조건에 맞는 행이 없으면 삭제되지 않음
UPDATE 명령어를 통한 셀 수정
update 테이블명 set 열1=값1, 열2=값2,…
where 조건식
- 여기서 사용되는 열1 = 값1 의 (=)는 같다는 뜻이 아니고 할당을 의미함 (비교연산자가 아닌 대입 연산자)
- 값들은 항상 ‘상수’로 표기해야 함
- where문을 사용하지 않으면 모든 행이 갱신됨
#no가 2인 행의 a 열을 'xyz'로 바꿔보기
update sample41 set a='xyz'
where no = 2;
#모든 행 바꾸고 싶다면?
update sample41 set no = no+1
select * from sample41;
#복수의 열을 갱신할 때
update sample41 set a = 'xyz', b = "2024-08-16"
where no = 2;
#셀의 값을 null로 갱신할
update sample41 set a = null"
where no = 2;Q1. Employee 테이블에서 전화번호가 +로 시작하지 않는 직원의 전화번호 를 +1로 시작하도록 변경해보기
update employee
set Fax = concat("+", fax)
where fax like "1%";Q2. 새로운 직원을 Employee 테이블에 추가해보기 (ID = 9, LastName = John, FirstName= Doe)
#직접 null을 넣는
insert into employee values (9, "john", "Doe", null, null, null, null,null,null,null,null,null,null,null,null);
#필드명을 고른 후 선택하는 법 - 나머지는 자동으로 null이 됨
insert into employee(EmployeeId, lastname, firstname)
values (9, "john", "doe");집계함수 및 서브쿼리
집계함수 (Count, sum, avg, mim, max)
count - 인수로 주어진 집합의 개수
count(집합)
select count(*) from sample51;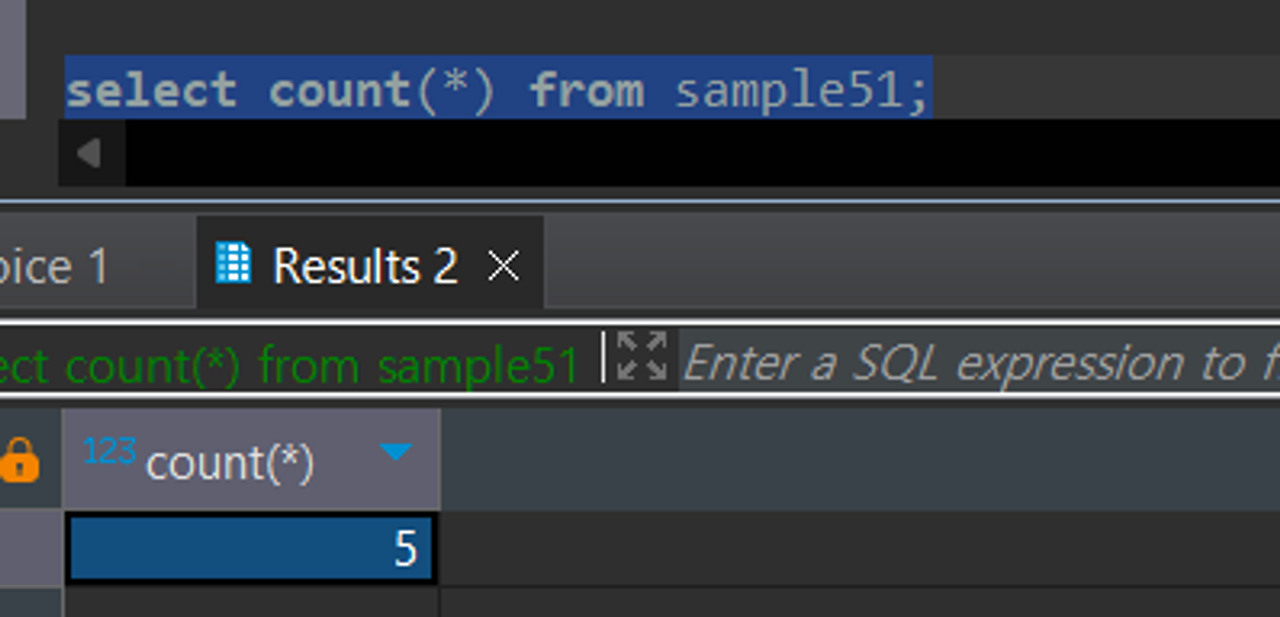
다섯개의 행이 있다면 5로 나옴
where과 함께 쓰
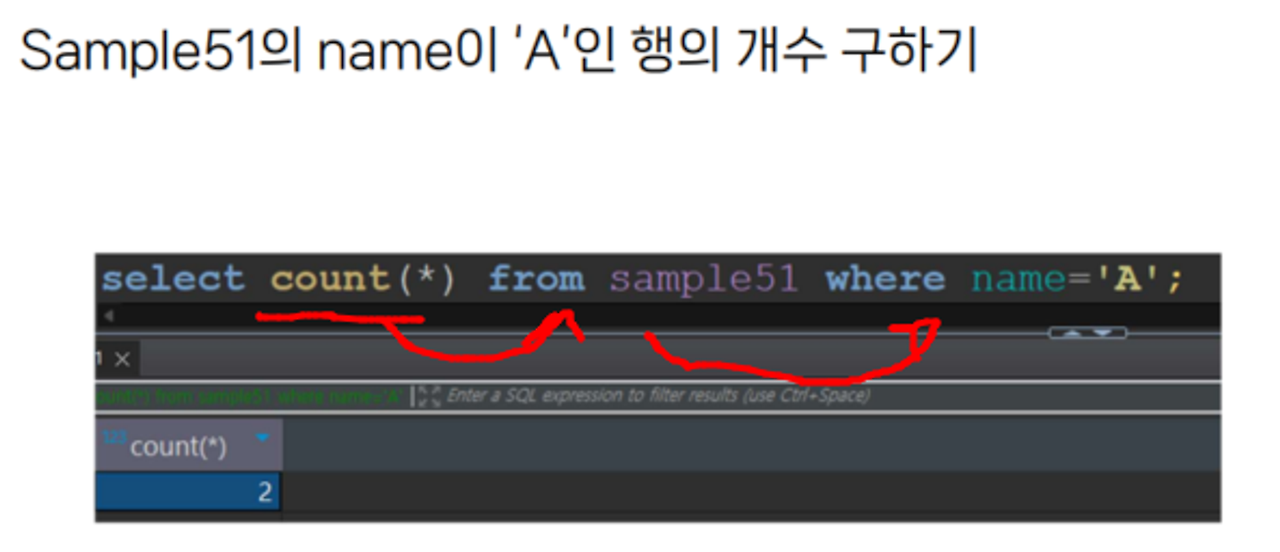
select 구는 where 구보다 나중에 내부적으로 처리됨.
따라서 where 구로 조건을 지정하면, 검색된 행이 count 함수로 넘겨져서 집계
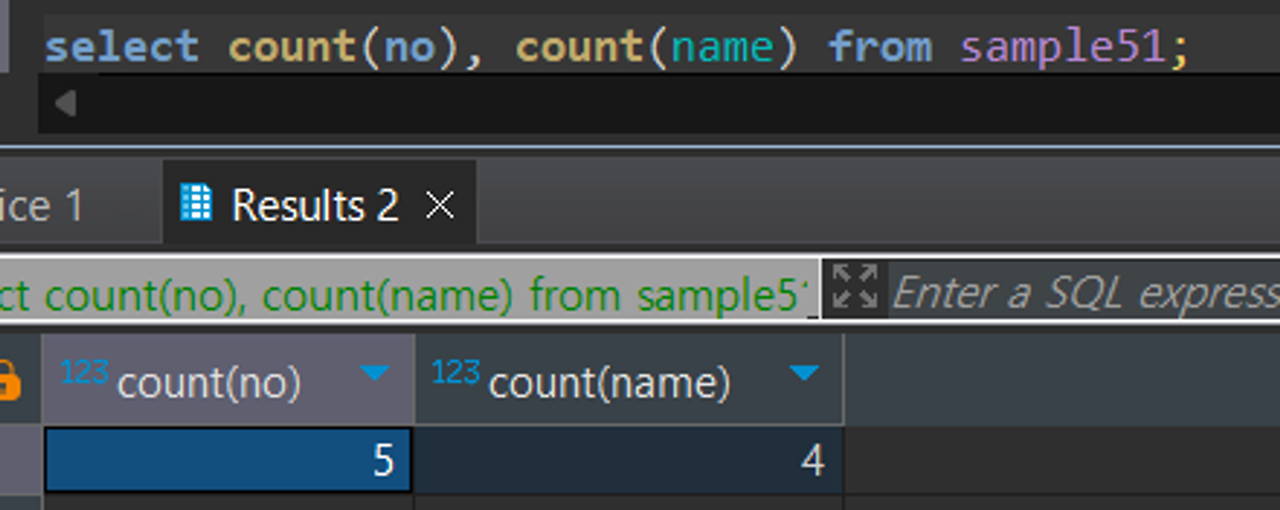
- Count의 인수로 * 대신 열 명을 지정할 수도 있습니다. 열 명을 지정하면 그 열에 한해서 행의 개수를 구할 수 있습니다. (보통 열의 개수를 구하기 위해서 사용함)
- null 값을 어떻게 취급하는지가 매우 중요
select count(no), count(name) from sample51; 을 하면 null값 때문에 답이 다르게 나옴
count(*)은 행의 개수
count(열 명) → null값 제외 값 개수
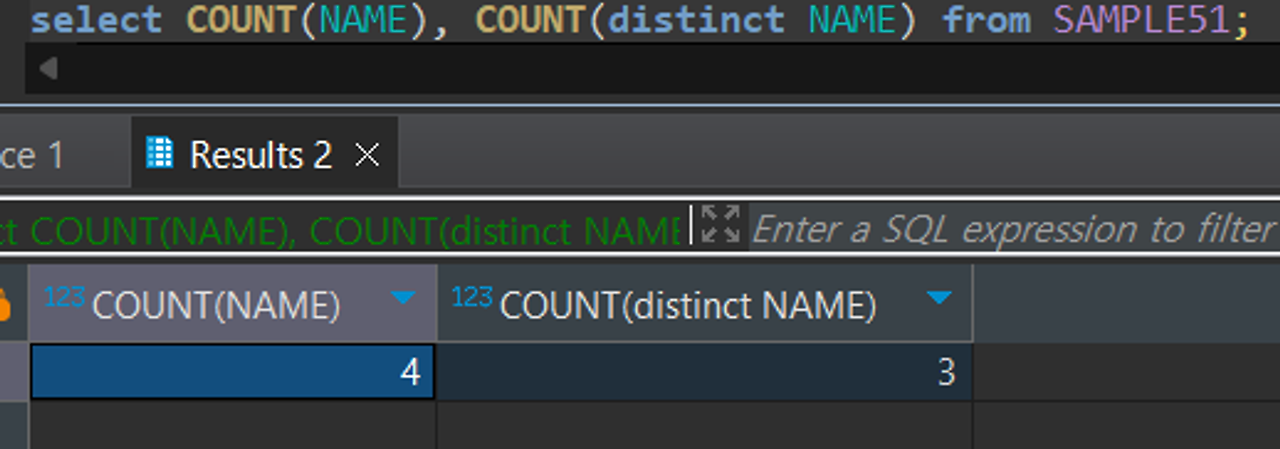
DISTINCT 중복 제거하구 개수 구하기
SELECT DISTINCT 열명1, 열명2…
FROM 테이블명
SELECT COUNT(DISTINCT 열명) FROM 테이블명
SUM으로 합계구하기
SUM([ALL|DISTINCT]집합)
SUM 집계 함수를 통해서는 집합의 합계를 구할 수 있음
예를들어 SAMPLE51테이블의 quantity를 모두 합하려면 quantity라는 집합을 sum 함수의 인자로 넣어서 합계를 구할 수 있음
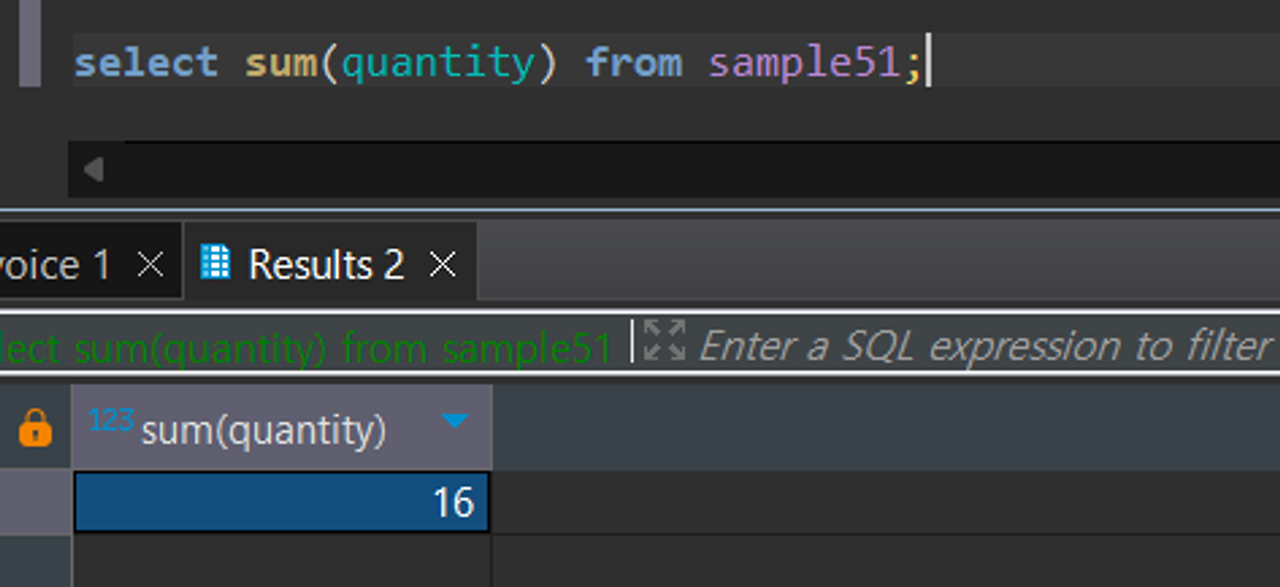
- sum도 count와 마찬가지로 null값 무시
- sum을 비롯해 avg, min, max 함수도 같은 용도로 쓰이는데, “수치형”데이터만 연산할 수 있음
Track 테이블을 사용해 다음 정보 조회하삼쿼리를 작성하세요:
전체 트랙 수
전체 트랙 총 재생 시간 (밀리초)
평균 트랙 길이 (초 단위로 변환)
가장 짧은 트랙의 길이 (초 단위)
가장 긴 트랙의 길이 (분 단위로 변환)
모든 트랙의 용량
평균 트랙 용량
select * from track;
desc track;
select count(*), sum(milliseconds), avg(Milliseconds)/1000 ,
min(Milliseconds)/1000 , max(Milliseconds)/1000*60, sum(bytes), avg(bytes)
from track;SQL은 들여쓰기나 띄어쓰기가 크게 중요하지 않음
줄 나눔도 가독성을 위한 것
SELECT * 만 잘 띄워서 작성해주면 됨
GROUP BY 그룹화
집계함수의 활용 범위를 넓히기 위해서, 행들을 그룹화하는 방법
SELECT * FROM 테이블 명
GROUP BY 열1, 열2
- GROUP BY를 통해, 집계함수로 넘겨줄 집합을 그룹으로 나눌 수 있음
- 그룹화를 통해 집계함수의 활용범위를 넓힐 수 있음
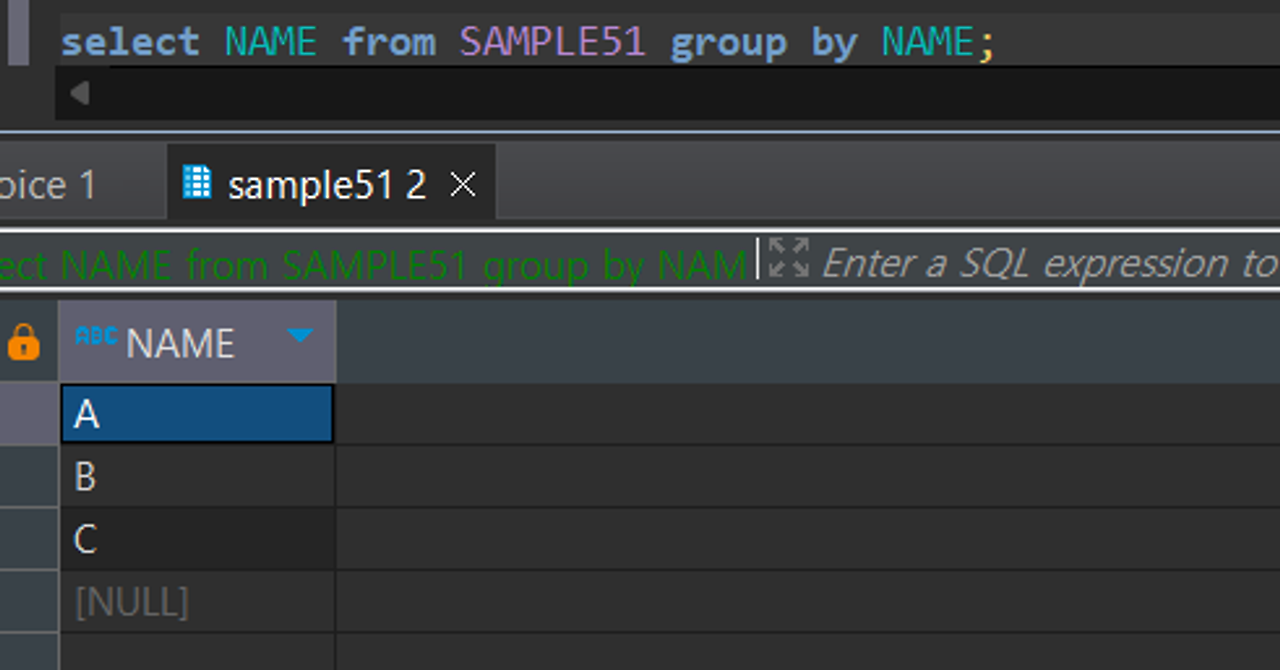
- GROUP BY를 통해서 지정된 열의 값이 같은 행은 하나의 그룹으로 묶임
- 열을 그룹화해 사용 가능
#NAME으로 그룹화 후 그룹별 행의 개수와 합계 계산
SELECT NAME, COUNT(NAME), SUM(QUANTITY)
FROM SAMPLE51
GROUP BY NAME;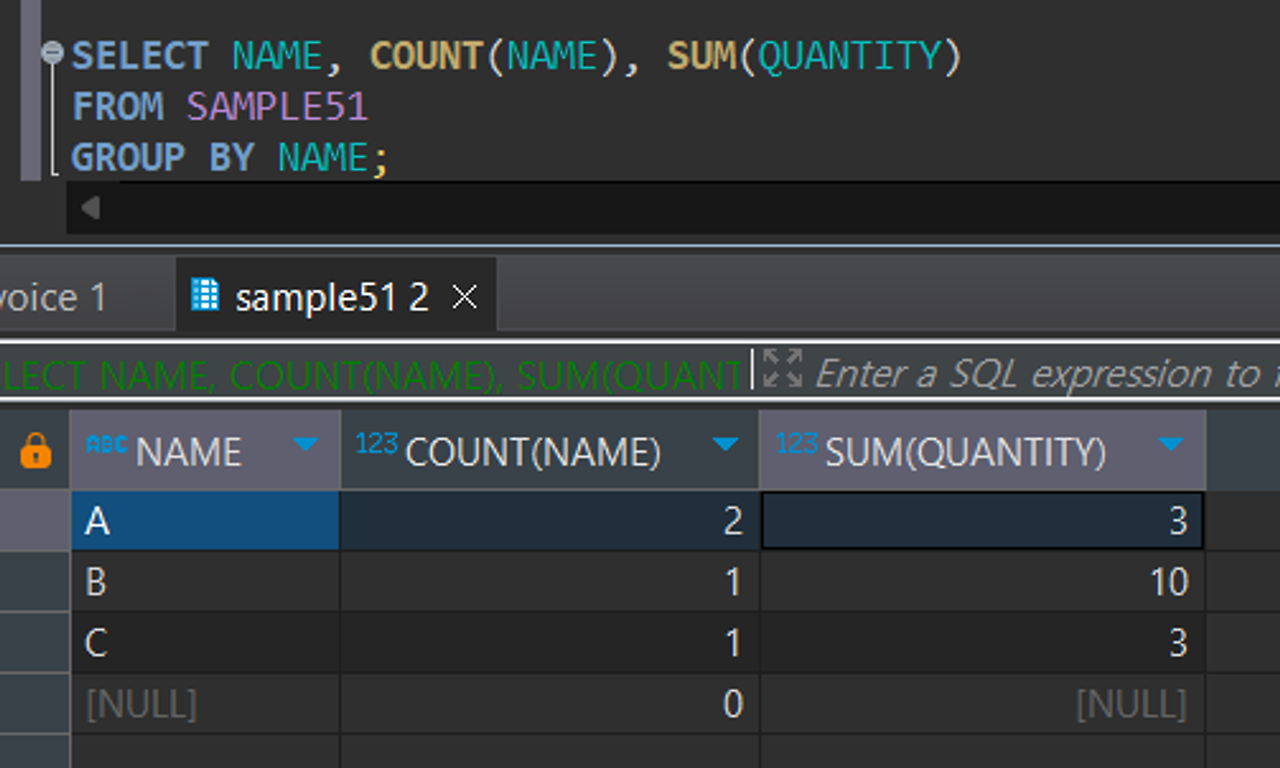
내부처리 순서
WHERE → GROUP BY → SELECT → ORDER BY
'sesac' 카테고리의 다른 글
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 프로젝트(1)_olist 데이터 파악 및 전처리 (0) | 2024.07.12 |
|---|---|
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(4)_GROUP BY, IN, JOIN (0) | 2024.07.09 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(2)_메타 문자 ORDER BY, OFFSET, 함수 (0) | 2024.07.05 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(1)_SQL 설치 및 조건 찾기 (MY SQL, SQL 불러오기) (1) | 2024.07.05 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | 엑셀 교육(1)_엑셀과 가설검정 (0) | 2024.06.24 |



