SQL 쿼리 사관학교
GROUP BY
select * from테이블 명
group by 열1, 열2
group by - 열을 그룹화 가능
group by에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 select에 기술해서는 안됨
select no, name, quantity from sample51 group by name;
집계함수는 where 구의 조건식 사용 불가
✅그래서 having구를 사용해 집계함수에서 조건식 지정 가능
select 열명 from 테이블명
group by 열명 having 조건식
sample51테이블의 name별로 그룹화하여 그룹별 행의 개수가 1인것만 출력해보기

내부처리순서
where → group by → having → select → order by
having에서는 별명 사용 불가능 (as ㅇㅇ)
별명을 짓는 건 보통select에서 함 (from은 테이블명 짓는 것)
select에서 지은 별명은 order by에서만 쓸 수 있
✅group by하지 않은 열은( 집계함수를 사용하지 않은 채 )select에 기술해서는 안됨

track 테이블 사용해 다음 정보 조회


#내가 쓴 식
select composer, count(trackid) as track_count,
round(sum(Milliseconds)/ 60000 ,1) as minute_sum,
count(unitprice) as price_count
from track
group by composer
having composer is not null and count(unitprice) >= 5 and round(sum(Milliseconds)/ 60000 ,1)>=30
order by count(trackid) desc;
#멘토님 식
SELECT
Composer,
count(*) AS trackcount,
sum(Milliseconds/60000) AS totalDuration,
sum(UnitPrice)
FROM track
WHERE Composer IS NOT NULL
GROUP BY Composer
HAVING count(*) >= 5 AND sum(Milliseconds/60000) > 30
ORDER BY trackcount DESC, totalDuration DESC;*group by 전에 where 사용 가능
서브쿼리
서브쿼리는 SELECT명령에 의한 데이터 질의, 상부가 아닌 하부의 부수적인 질문을 의미함.
- 보통 다른 쿼리 내부에 포함되어있는 SELECT문을 의미
서브쿼리는 주로 where 구에서 사용됨
select productname, price
from products
where price > (select avg(price) from prodcuts);
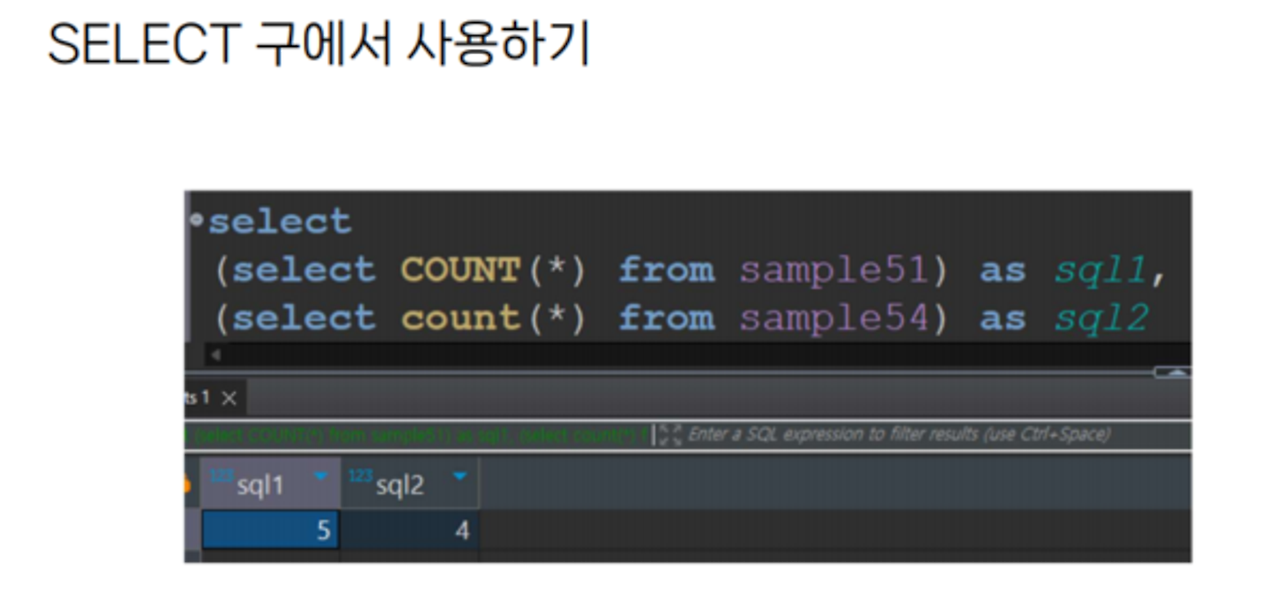
SELECT구에서 사용하기
select구에서 서브 쿼리 사용가능하며 단일 값을 반환함
- 서브쿼리를 사용할때는 SELECT 명령이 어떤 값을 반환하는지가 중요

- -하나의 값을 반환하는 패턴 = “스칼라 값“
- 복수의 행이 반환되지만 열은 하나인 패턴
- 하나의 행이 반환되지만 열이 복수인 패턴
- 복수의 행, 복수의 열이 반환되는 패턴


WHERE 구 - 스칼라값으로 자주 사용됨.
SET 구 - 다른 테이블의 데이터를 기반으로 업데이트할 때 자주 쓰임.
SELECT 구 -전체 데이터셋과 각 행을 비교할때 자주 쓰임.
FROM 구 -복잡한 집계나 조인 결과를 임시 테이블처럼 사용할 때 자주 쓰임
#Q1. 평균 곡 길이보다 긴 곡들의 이름과 길이(milliseconds)를 조회하세요.
#( WHERE 절에 서브쿼리를 사용)
#1 - 내가 쓴 값 - 멘토님거랑 같음
select NAME, milliseconds
from track
where Milliseconds >
(select avg(milliseconds) from track);
#Q2. 각 장르별 평균 곡 길이(초 단위)를 조회하세요(FROM 절에 서브쿼리 사용)
#2 -> 답 안나옴
select genreid, avg(milliseconds)/1000 as seconds
from (select genreid, from track
group by genreid) ms;
#멘토님꺼
select *
from(select genreid, avg(milliseconds)/1000
from track t
group by genreid) dd;
#이걸 from문에 넣어 가상 테이블로 사용가능하다는 것을 보여주기 위한 문제,
from 쓸 때는 별명 꼭 써주기
#Q3. 모든 트랙의 이름, 길이(밀리초), 그리고 평균 트랙 길이와의 차이를조회하세요.
#(SELECT 절의 연산에 스칼라 서브쿼리 사용)
#3
select name, milliseconds,
milliseconds - (select avg(milliseconds) from track) difference
from track;
상관 서브쿼리 EXISTS
상관 서브쿼리’는 EXISTS 라는 술어로 조합하여서 사용하는 서브쿼리
[not] exists (Select 명령)
EXISTS - 집합 대 집합 비교
- EXISTS 술어를 사용하면, 서브쿼리가 반환하는 결과값이 있는지 조사 가능

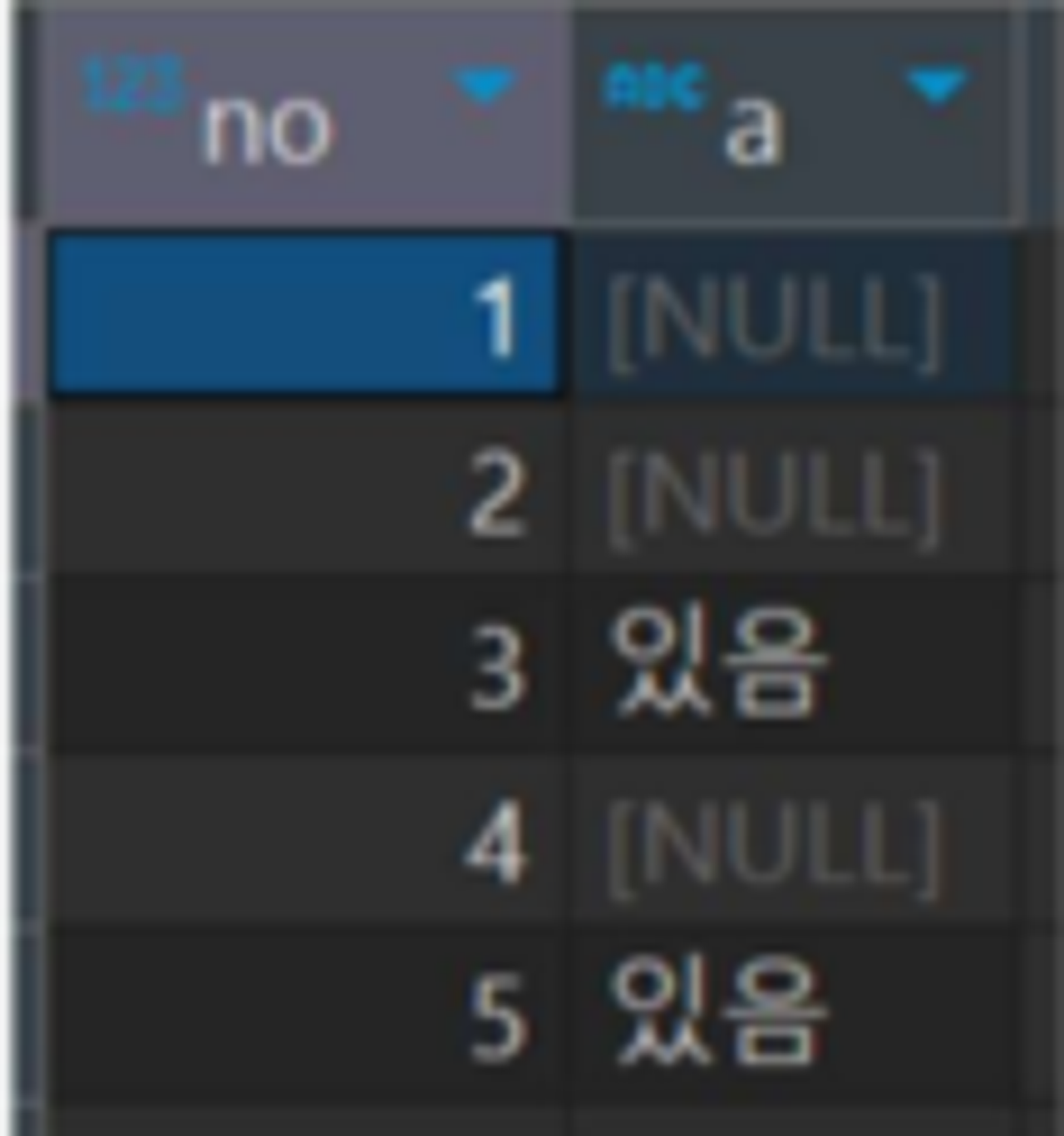
- 위 상관 서브쿼리의 실행 결과로, 변한 sample551 테이블
- 서브쿼리를 사용한 집합간의 비교를 할 때, EXISTS를 사용
- NOT EXISTS를 통해서, 행이 존재하지 않는 경우에 참이 되게 하는 것도 가능
Update sample551 set a = "없음" where
not exists (select * from sample552 where no2 = no)상관서브쿼리
- 상관 서브쿼리를 사용해, 다른테이블의 상황을 판단하고 update를 갱신할 수 있음
- select 명령이나, delete명령으로도 서브쿼리를 사용할 수 있음
select * from sample551 where
not exists (select * from sample552 where no2 = no);IN
- 보통 스칼라 값 (하나의 값)을 비교할 때는 “=”연산자 사용
- 집합을 비교할 때는 “IN”을 사용 → 집합 안의 값이 존재하는지 조사할 수 있음
- 서브쿼리를 사용할 때, IN을 통해 비교하는 경우도 많음
열명 IN (집합)
#where문 버전
Where no = 3 or no = 5
#in 버전
select * From sample551
where no in (3, 5)- in의 오른쪽에 집합을 지정, 이 때 서브쿼리도 위치할 수 있음
- NOT IN 사용 가능
SELECT * FROM sample551
where no in (select no2 from sample552);
select * from sample551
where no not in (select no2 from sample552);- in에서는 집합 안에 null 값이 있어도 무시하지 않음
- 다만, null = null을 제대로 계산할 수 없어서 in을 사용한 null값 비교 어려움
→null을 비교할 때는 is null을 사용해야 함
not in의 경우, 집한 안에 null이 있으면, 참을 반환하지 않음 (그 결과는 unknown이 됨)
#USA에 있는 고객들의 주문 정보를 조회하세요.
#각 고객별로 고객 ID, 주문횟수,총 주문 금액을 표시하고, 총주문금액이 큰 순서대로 정렬
select customerid, count(customerid), sum(total), billingcountry
from invoice
where billingcountry in (select "usa" from invoice i )
group by CustomerId, BillingCountry
order by sum(total) desc;
내가 쓴 식
처음에 “usa”가 아닌 usa로 해서 답이 안 나옴
복수의 테이블
합집합과 결합

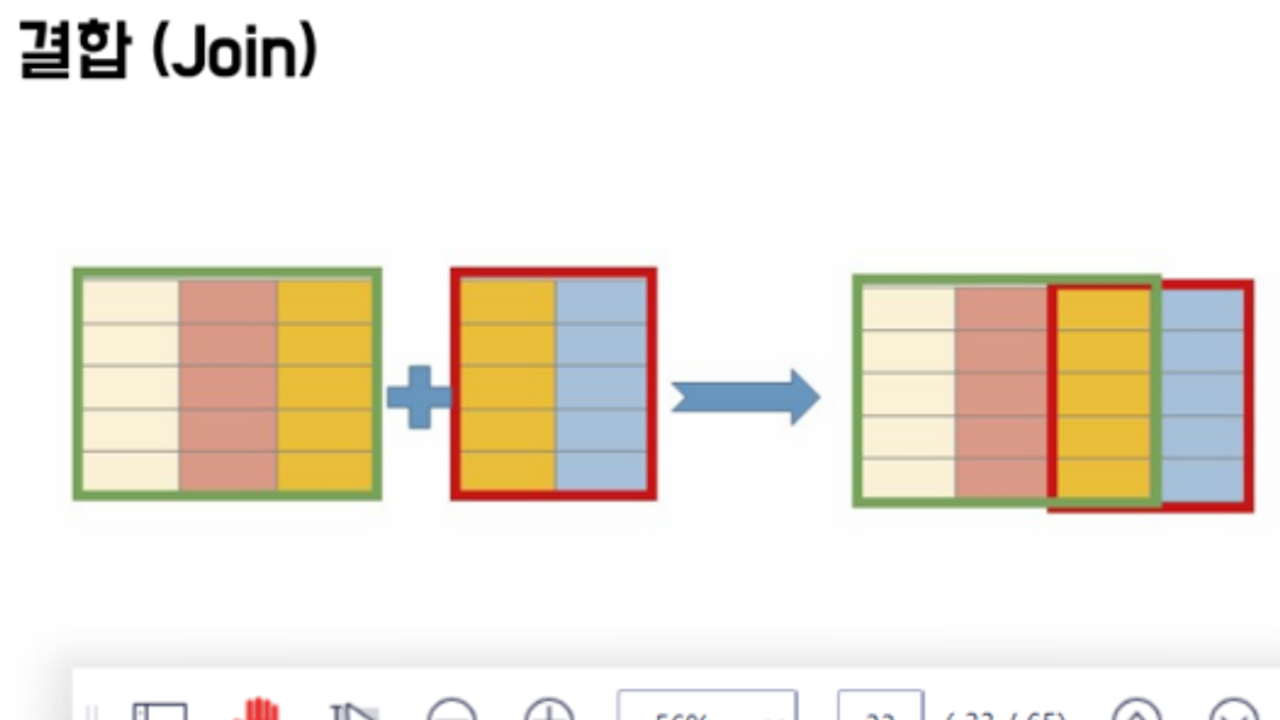
- 합집합: 데이터가 추가되는 형식으로 아래에 연결됨
- 결합(조인): 칼럼이 추가되는 형식으로 옆으로 연결됨
합집합(union)
두 개 이상의 select 명령을 하나로 연계해 질의 결과를 얻을 수 있다
select문
union (All)
select문 (order by 열명);
ex. 동일한 매출의 10월, 11월, 12월 자료를 4분기 자료로 합침
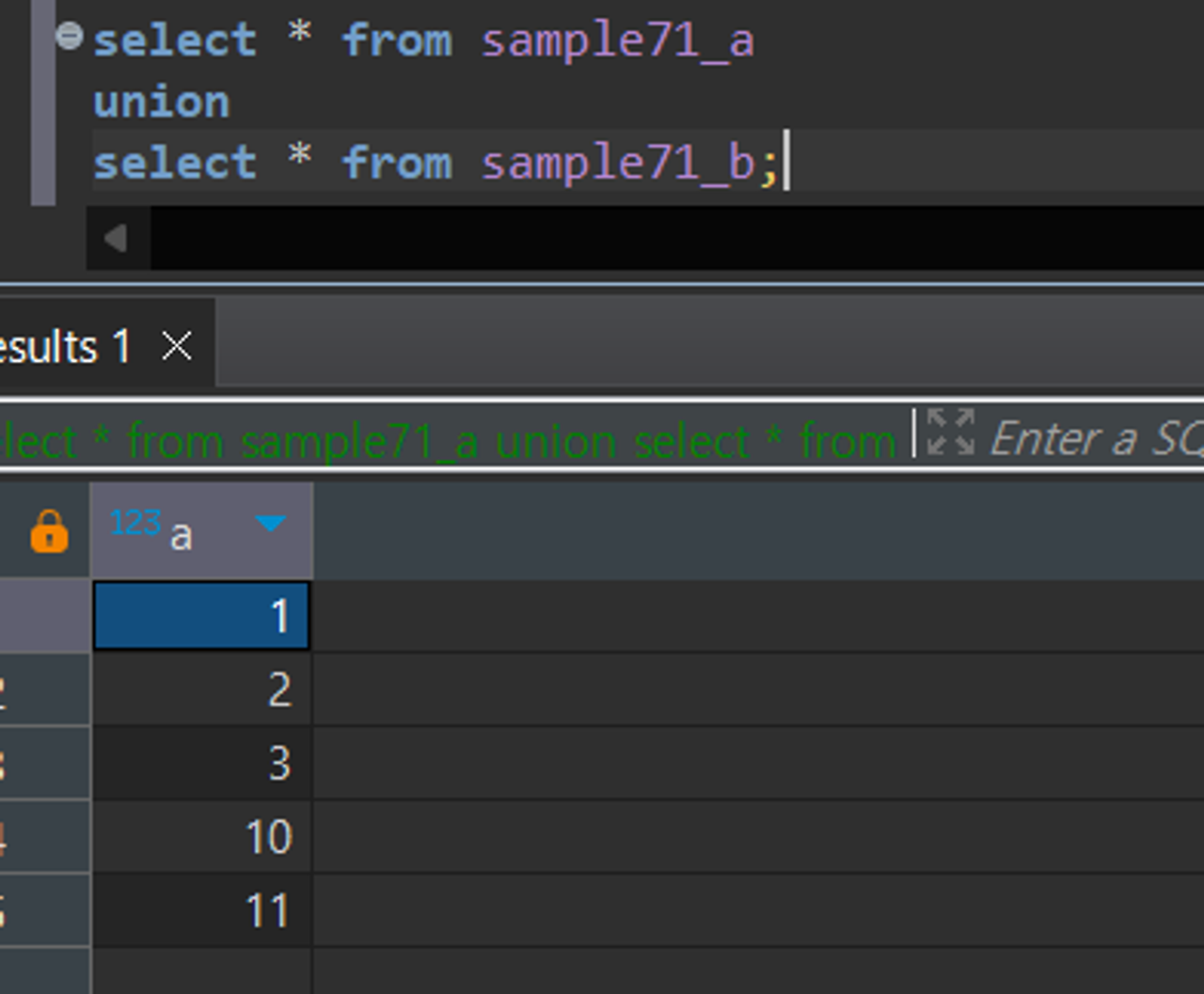
- union을 이용해 여러 개의 select 명을 하나로 묶을 수 있음
- Sample71_a와 sample71_b는 같은 열 개수와, 자료형을 갖고 있기에 합칠 수가 있음
- 다른 열을 갖고 있는 것을 합집합시키고 싶을 때는, SELECT 문에 열 명을 명시

- select문의 순서가 바뀐다면 order by를 지정하지 않았을 때, 결과값 데이터의 순서가 바뀔 수도 있음
- union에서 order by를 사용하면, 마지막select문에만 지정하는 게 좋음

합치는 열의 이름이 다를 수 있기 때문에 별명을 붙이는 것이 일반적
앞서 배운 DISTINCT가 UNION 에서는 기본적으로 포함되어 있
- 만약, Union시 중복을 제거하고 싶지 않다면 UNION ALL을 사용
결합(join) - SQL에서 매우 중요한 파트
*고유한 열을 지목해야 하기 때문에 키 개념이 매우 중요
- 여러 개로 나뉜 데이터를 하나로 묶어서 결과를 내는 방법을 테이블 결합이라고 함

JOIN은 내부결합/ 외부결합 두 가지로 나뉨
- 내부결합(이너 조인)은 테이블 두 개에서 서로 중복되는 값만 나타냄
SELECT *
FROM 테이블명
INNER JOIN 테이블명2 ON 결합조건
- 상품2 테이블과 메이커 테이블을 합치는 것으로 내부결합 (INNER JOIN)을 해봄

*테이블에도 별명을 붙일 수 있음 → 어떤 테이블에서 온 열인지 명시하면서 이너조인을 실행하는 것 추천
SELECT S.상품명, M.메이커명
from 상품2 s inner join 메이커 m
on s.메이커코드 = m.메이커코드;*select문을 통해서 join한 것은 가상의 테이블로 별도로 테이블을 저장되지는 않음
저장하려면 따로 저장해줘야 함
join예시
SELECT
c.LastName,
c.FirstName,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
Customer c
INNER JOIN Invoice i ON c.CustomerId = i.CustomerId
INNER JOIN InvoiceLine il ON i.InvoiceId = il.InvoiceId
INNER JOIN Track t ON il.TrackId = t.TrackId
INNER JOIN Album a ON t.AlbumId = a.AlbumId
ORDER BY
c.LastName, c.FirstName;관계#각 장르(Genre)별로 트랙(Track)의 수와 총 재생 시간(Milliseconds)을 조회하세요.도 보는


#각 장르(Genre)별로 트랙(Track)의 수와 총 재생 시간(Milliseconds)을 조회하세요.
select g.name, count(t.trackid), sum(t.milliseconds)
from genre g inner join track t
on t.genreid = g.genreid
group by g.name;
#고객(Customer)의 이름과 그들이 주문한 총 금액을 조회하세요.
select concat(c.lastname, ' ',c.firstname)as name, sum(i.total)
from customer c inner join invoice i
on c.customerid = i.CustomerId
group by concat(c.lastname, ' ',c.firstname);'sesac' 카테고리의 다른 글
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 프로젝트(1)_olist 데이터 파악 및 전처리 (0) | 2024.07.12 |
|---|---|
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(3)_문자열 연산, 날짜연산, 데이터 추가, 집계 (0) | 2024.07.08 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(2)_메타 문자 ORDER BY, OFFSET, 함수 (0) | 2024.07.05 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | SQL 교육(1)_SQL 설치 및 조건 찾기 (MY SQL, SQL 불러오기) (1) | 2024.07.05 |
| SeSAC 전z전능 분석가 성동2기 데이터 분석가 | 엑셀 교육(1)_엑셀과 가설검정 (0) | 2024.06.24 |



